

常常写网络爬虫的同学们,毫无疑问了解 Cloud Flare 的五秒盾。如果你沒有应用一切正常的电脑浏览器浏览网址的情况下,它会回到以下这一段文本:
即便 你将 Headers 带详细,应用代理商 IP,也会被它发觉。大家看来一个事例。Mountain View Whisman students sent home after children test positive for COVID-19 [1] 本文,应用一切正常电脑浏览器浏览,实际效果如下图所显示:
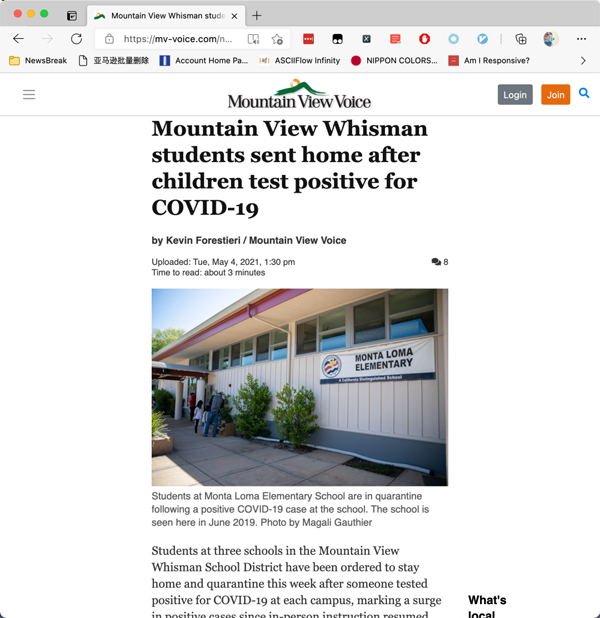
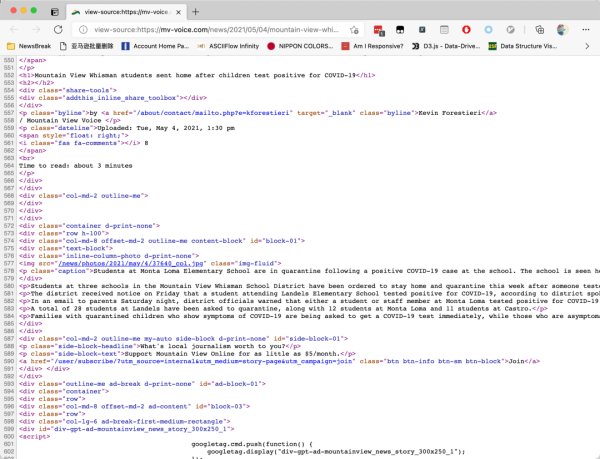
立即查询初始的网页源代码,能够见到,文章标题和文章正文就在源码里边,表明新闻的标题和文章正文全是后端开发3D渲染的,并不是多线程载入。如下图所显示:
如今,大家应用 requests,携带详细的请求头来浏览这一网址,实际效果如下图所显示:
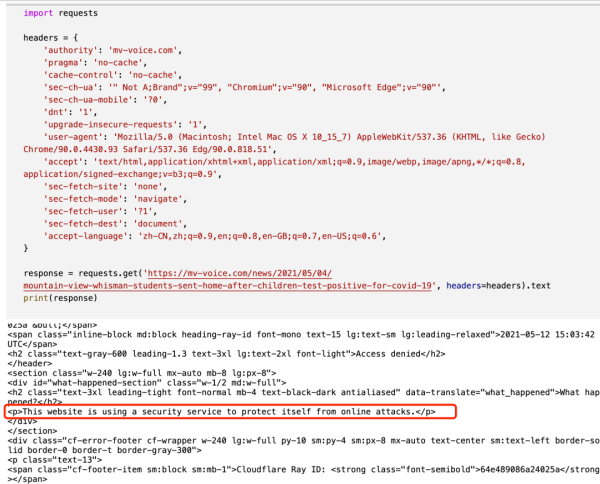
网址鉴别到网络爬虫个人行为,取得成功把网络爬虫要求遮挡了。许多同学们在这个时候就早已无计可施了。由于它是网络爬虫的第一次要求就被遮挡了,因此网址并不是检验的 IP 或是浏览頻率,因此即应用代理商 IP 也于事无补。而如今即便 携带了详细的请求头都能被发觉,那还有什么办法绕开这一检验呢?
事实上,要绕开这一5秒盾比较简单,只必须应用一个第三方库,叫做cloudscraper。我们可以应用pip来安裝:
- python3 -m pip install cloudscraper
安裝进行之后,只必须应用3行编码就能绕开 Cloud Flare 的5秒盾:
- import cloudscraper
- scraper = cloudscraper.create_scraper()
- resp = scraper.get('总体目标网址').text
大家或是以上边的网址为例子:
- import cloudscraper
- from lxml.html import fromstring
- scraper = cloudscraper.create_scraper()
- resp = scraper.get('https://mv-voice.com/news/2021/05/04/mountain-view-whisman-students-sent-home-after-children-test-positive-for-covid-19').text
- selector = fromstring(resp)
- title = selector.xpath('//h1/text()')[0]
- print(title)
运作实际效果如下图所显示:
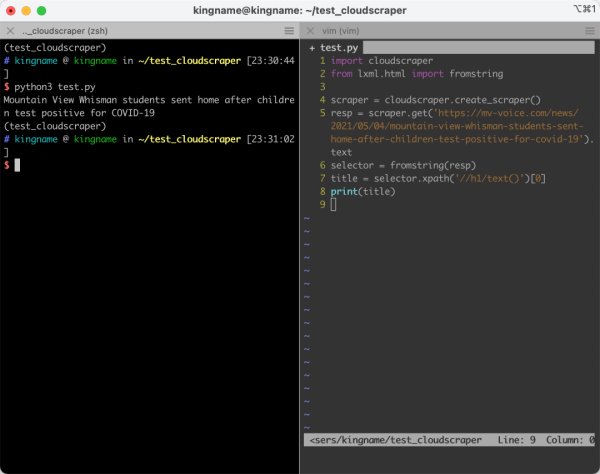
破盾取得成功。
CloudScraper[2] 十分强劲,它能够提升 Cloud Flare 绿色版每个版本号的五秒盾。并且它的插口和 requests 保持一致。原先用 requests 怎么写代码,如今只必须把requests.xxx改为scraper.xxx就可以了。
参考文献
[1]Mountain View Whisman students sent home after children test positive for COVID-19 : https://mv-voice.com/news/2021/05/04/mountain-view-whisman-students-sent-home-after-children-test-positive-for-covid-19
[2]CloudScraper: https://github.com/venomous/cloudscraper
【责编:武晓燕 TEL:(010)68476606】




