
伴随着 Facebook 的 DETR (ECCV 2020)[2] 和Google的 ViT (ICLR 2021)[3] 的明确提出,Transformer 在视觉效果行业的运用逐渐快速提温,变成时下视觉效果科学研究的第一网络热点。但视觉效果 Transformer 受制于固定不动长短的部位编号,不可以像 CNN 一样立即解决不一样的键入规格,这在非常大水平上限定了视觉效果 Transformer 的运用,由于许多视觉效果每日任务,如检验,必须在检测时动态性更改键入尺寸。
一种解决方法是对 ViT 中部位编号开展插值法,使其融入不一样的图片尺寸,但这类计划方案必须再次 fine-tune 实体模型,不然結果会下降。
近期,美团外卖明确提出了一种用以视觉效果 Transformer 的隐式标准部位编号 CPE [1],放开了显式部位编号给键入规格产生的限定,促使 Transformer 便于解决不一样规格的键入。试验说明,运用了 CPE 的 Transformer 特性好于 ViT 和 DeiT。
毕业论文详细地址:https://arxiv.org/pdf/2102.10882.pdf
新项目详细地址:https://github.com/Meituan-AutoML/CPVT(将要开源系统)
情况
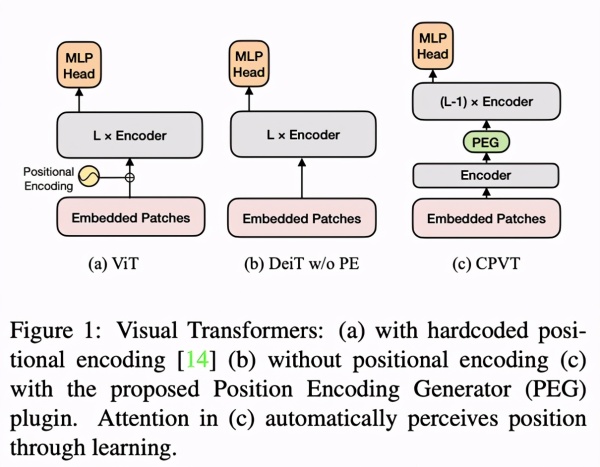
Google的 ViT 方式 一般将一幅 224×224 的照片打撒成 196 个 16×16 的照片块(patch),先后对其做线形编号,进而获得一个键入编码序列(input sequence),使 Transformer 能够 像解决标识符编码序列一样处理照片。另外,为了更好地保存每个照片块中间的位置信息,添加了和键入编码序列编号层面同长的部位编号。DeiT [4] 提升了 ViT 的训炼高效率,不会再必须把大数据(如 JFT-300M)做为预训炼的限定,Transformer 能够 立即在 ImageNet 上训炼。
针对视觉效果 Transformer,部位编号必不可少
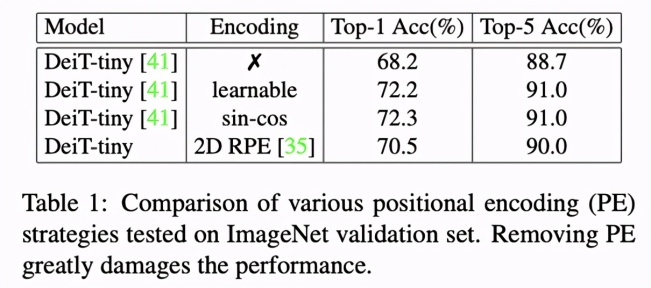
在 ViT 和 CPVT 的试验中,我们可以发觉沒有部位编号的 Transformer 特性会发生显著降低。此外,在 Table 1 中,可学习培训(learnable)的部位编号和正余弦(sin-cos)编号实际效果贴近,3D 的相对性编号(3D RPE)特性较弱,但依然好于除掉部位编号的情况。
美团外卖、澳大利亚悉尼高校明确提出新式部位编码方式
部位编号的设计方案规定
显式的部位编号限定了键入规格,因而美团外卖此项科学研究考虑到应用隐式的依据键入而转变的拉长编码方式。除此之外,它还必须达到下列规定:
维持非常好的特性;
防止排序不变(permutation equivariance);
便于完成。
根据所述规定,该科学研究明确提出了标准编号制作器 PEG(Positional Encoding Generator),来转化成隐式的部位编号。
转化成隐式的标准部位编号
在 PEG 中,将上一层 Encoder 的 1D 輸出变产生 3D,再应用转换控制模块学习培训其位置信息,最终再次形变到 1D 室内空间,与以前的 1D 輸出求和以后做为下一个 Encoder 的键入,如 Figure 2 所显示。这儿的转换模块(Transoformation unit)能够 是 Depthwise 卷积和、Depthwise Separable 卷积和或别的更加繁杂的控制模块。
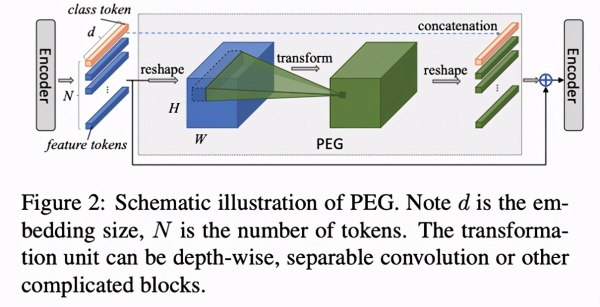
将 PEG 插进到实体模型中(如 Figure 1 中加上在第一个 Encoder 后),就可以对每个 Encoder 加上部位编号信息内容。这类编号益处取决于不用显式特定,长短能够 依键入转变而转变,因而被称作隐式的标准部位编号。
试验
ImageNet 数据
该科学研究将加上了 PEG 的 Vision Transformer 实体模型取名为 CPVT(Conditional Position encodings Visual Transformer)。在 ImageNet 数据上,同样数量级的 CPVT 实体模型特性好于 ViT 和 DeiT。归功于隐式标准编号能够 依据键入动态性调节的特点,根据 224×224 键入训炼好的实体模型能够 立即解决 384×384 键入(Table 3 最终一列),不用 fine-tune 就能立即得到特性提高。比较之下,别的显式编号沒有 fine-tune 则会发生特性损害。
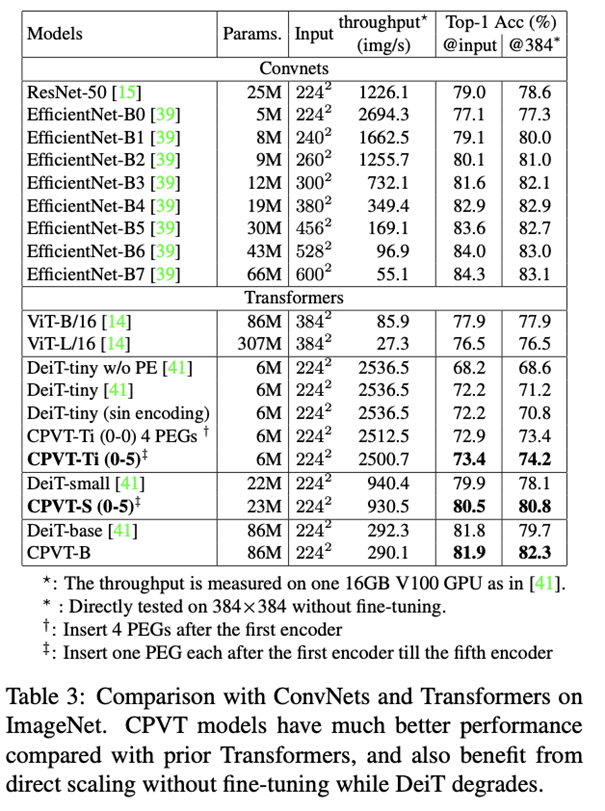
与别的编码方法的比照
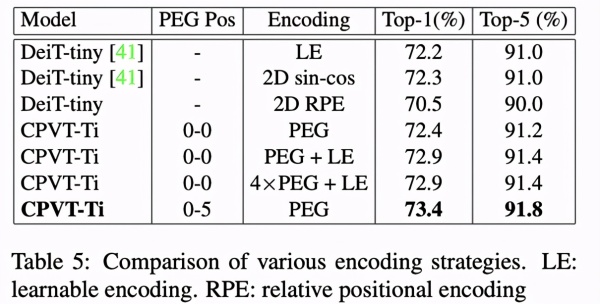
Table 5 得出了 CPVT-Ti 实体模型在不一样编号对策下的主要表现。在其中在从第 0 个到第 5 个 Encoder 各插进一个 PEG 的特性最优化,Top-1 准确度做到 73.4%。CPVT 独立应用 PEG 或与可学习培训编号紧密结合也好于 DeiT-tiny 在各种各样编号对策下的主要表现。
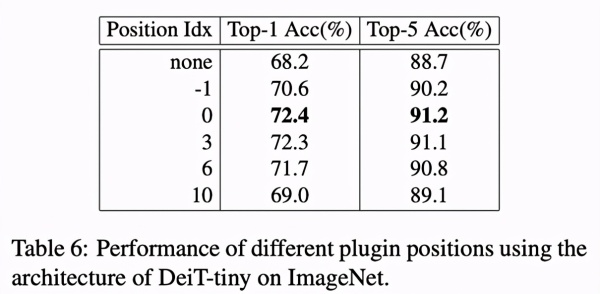
PEG 在不一样部位的功效
ViT 主杆由 12 个 Encoder 构成,CPVT 比照了 PEG 坐落于 -1、0、3、6、10 等处的結果。试验说明,PEG 用以第一个 Encoder 以后主要表现最好是 (idx 0)。该科学研究觉得,放到第一个 encoder 以后不但能够 出示全局性的接纳域,也可以确保实体模型尽快地运用到位置信息。
结果
CPVT 明确提出的隐式部位编号是一个1394连接的通用性方式 。它放开了对键入规格的限定,因此有希望推动 Vision Transformer 在切分、检验、超分辨率等每日任务中的进一步运用,提高其特性。此项科学研究对事后 Vision Transformer 的发展趋势将造成积极主动的危害。





