
亲,显卡内存炸了,你的独立显卡快起烟了!
- torch.FatalError: cuda runtime error (2) : out of memory at /opt/conda/conda-bld/pytorch_1524590031827/work/aten/src/THC/generic/THCStorage.cu:58
想来它是全部炼丹师们最不愿见到的不正确,没有之一。
OUT OF MEMORY ,显而易见是显卡内存放不进你那么多的实体模型权重值也有中间变量,随后程序流程崩溃了。该怎么办,实际上方法有很多,立即清除中间变量,提升编码,降低batch,等等,都可以降低显卡内存外溢的风险性。
可是这篇说起的是上边这一切提升实际操作的基本,如何去测算大家所应用的显卡内存。学好如何计算出去大家设计方案的实体模型及其中间变量所占显卡内存的尺寸,想来知道这一点,大家对自身显卡内存也便会游刃有余了。
最先大家应当了解一下基础的信息量信息内容:
好,毫无疑问有些人会问为什么是1000而不是1024,这儿但是多探讨,只有说二种叫法全是恰当的,仅仅应用领域略有不同。这儿统一依照上边的规范开展测算。
随后大家说一下大家平时应用的空间向量所占的室内空间尺寸,以Pytorch官方网的数据类型为例子(全部的深度神经网络架构数据类型都遵照同一个规范):

大家只必须看左侧的信息内容,在平时的训炼中,大家常常应用的一般是这二种种类:
一般一个8-bit的整型变量所占的室内空间为 1B 也就是 9ait 。而32位系统的float则占 4B 也就是 32bit 。而双精度浮点型double和长整型long在平时的训炼中大家一般不容易应用。
ps:消費级独立显卡对单精度测算有提升,网络服务器等级独立显卡对双精度测算有提升。
换句话说,假定有一幅RGB三安全通道真彩色的图片,宽度各自为500 x 500,基本数据类型为单精度浮点型,那麼这幅图所占的显卡内存的尺寸为:500 x 500 x 3 x 4B = 3M。
而一个(256,3,100,100)-(N,C,H,W)的FloatTensor所占的室内空间为256 x 3 x 100 x 100 x 4B = 31M
很少对吧,没事儿,大戏才刚开始。
看上去一张图片(3x256x256)和卷积层(256x100x100)所占的室内空间并不算太大,那为何大家的显卡内存依然還是用的比较多,缘故非常简单,占有显卡内存比较多室内空间的并并不是大家键入图象,只是神经元网络中的中间变量及其应用optimizer优化算法时造成的大量的正中间主要参数。
大家最先来简易测算一下Vgg16这一net必须占有的显卡内存:
一般一个实体模型占有的显卡内存也就是两一部分:

照片来源于cs231n,这是一个典型性的sequential-net,由上而下很畅顺,我们可以见到大家键入的是一张224x224x3的三安全通道图象,能够 见到一张图象只占有 150x4k ,但上边是 155k ,这是由于这儿在预估的情况下默认设置的数据类型是8-bit而不是32-bit,因此最终的結果要乘上一个4。
我们可以见到,左侧的memory值意味着:图象键入进来,照片及其所造成的正中间卷积层所占的室内空间。大家都了解,这种各式各样的深层次卷积层也就是深层神经元网络开展“思索”的全过程:

照片从3安全通道变成64 --> 128 --> 256 --> 512 .... 这种全是卷积层,而大家的显卡内存也主要是她们占有了。
也有上边右侧的params,这种是神经元网络的权重值尺寸,能够 见到第一层卷积和是3x3,而键入图象的安全通道是3,輸出安全通道是64,因此很显而易见,第一个卷积层权重值所占的室内空间是 (3 x 3 x 3) x 64。
此外还有一个必须留意的是中间变量在backward的情况下会翻番!
举个事例,下边是一个计算图,键入 x ,历经正中间結果 z ,随后获得最后自变量 L :
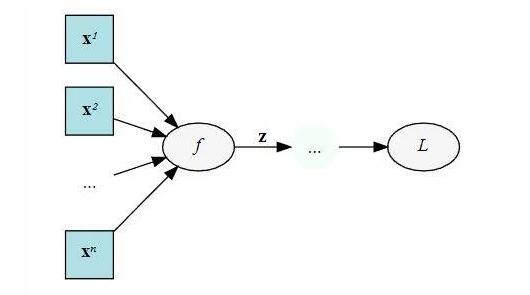
我们在backward的情况下必须储存出来的正中间值。輸出是 L ,随后键入 x ,我们在backward的情况下规定 L 对 x 的梯度方向,这个时候就必须在预估链 L 和 x 正中间的 z :
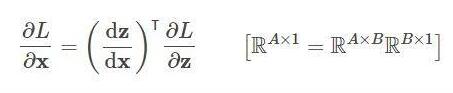
dz/dx 这一正中间值自然要保存出来以用以测算,因此粗略地可能, backward 的情况下中间变量的占有了是 forward 的二倍!
要留意,优化器也会占有大家的显卡内存!
为何,看这个算式:
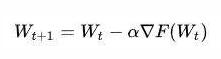
上式是典型性的SGD任意降低法的整体公式计算,权重值 W 在开展更新的情况下,会造成储存中间变量 ,也就是在提升的情况下,实体模型中的params主要参数所占有的显总量会翻番。
,也就是在提升的情况下,实体模型中的params主要参数所占有的显总量会翻番。
自然这仅仅SGD优化器,别的繁杂的优化器假如在预估时必须的中间变量多的情况下,便会占有大量的运行内存。
有主要参数的层即会占有显卡内存的层。大家一般的卷积层都是会占有显卡内存,而大家常常应用的激话层Relu沒有主要参数就不容易占有了。
占有显卡内存的层一般是:
而不占有显卡内存的则是:
实际测算方法:
小结一下,我们在整体的训炼中,占有显卡内存大约分下列几种:
但实际上,大家占有的显卡内存室内空间为何比大家基础理论测算的也要大,缘故大约是由于深度神经网络架构一些附加的花销吧,但是假如根据上边公式计算,基础理论推算出来的显卡内存和具体不容易差过多的。
提升除开优化算法层的提升,最基础的提升只不过也就一下几个方面:
- inplace





