

照片来源于 Pexels
不论是一个域,一个 BG,還是一个网站,尽管范畴大小不一,目标各有不同,但其高可用性的核心理念全是互通的,今日将自身对高可用性的一点点思索及其小结的“nPRT 公式计算”共享给大伙儿。
文中选用“高可用性是啥,为何要高可用性,如何做高可用性,为何那么做,手机软件风险性又在哪儿”的逻辑性来详细介绍。
高可用性是一种操纵风险性的工作能力
高可用性是一种朝向风险性设计方案,使系统软件具有操纵风险性,出示高些的易用性的工作能力。
为何要高可用性
针对一个企业来讲,“为何要高可用性”能够详细了解为“企业为何要(重装系统)高可用性”。
以企业为目标,从内看包含:人,手机软件(物),硬件配置(物);由外看包含:顾客,公司股东,社会发展;从本身看包含:企业。
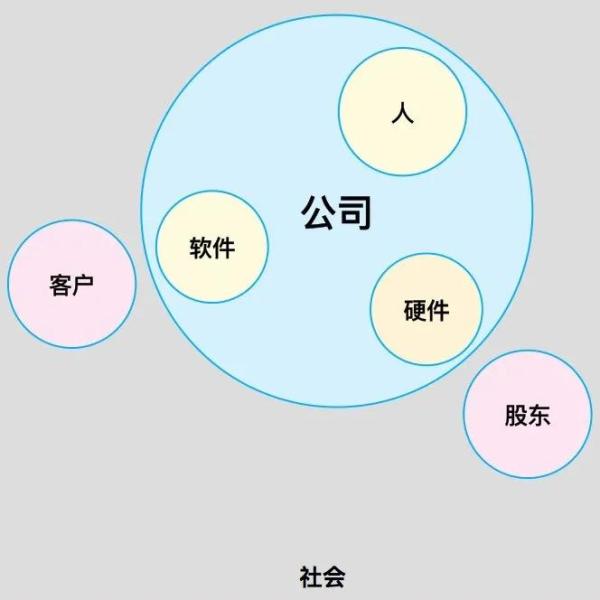
高可用性的前提,全部事情都并不是 100% 靠谱的:
诱因,人、物都并不是 100% 靠谱的:
从概率学视角剖析,但凡有可能会打错的,只需转变频次充足多,最后打错的几率会无尽趋于 1。
诱因,无高可用性,对外开放影响度是非常大的:
根因(实质):操纵风险性。
从企业本身视角:操纵风险性,确保企业使用价值,防止伤到压根。
怎样做高可用性
怎样做高可用性,实质上便是:怎样操纵风险性。
风险性有关定义
风险性:指将来会产生伤害的一种概率,但具体未产生,记作r。
常见故障:指已产生或已经产生伤害的一种客观事实,是风险性变实际的結果。
风险性几率:指一个风险性变常见故障的几率。用它来表明风险性开启为常见故障的难度系数水平,记为 P(r)。
常见故障危害范畴:指在单位时间内,一个常见故障导致的伤害危害,记为 R(r)。
常见故障危害时间:指一个常见故障不断的時间,记为 T(r)。
常见故障影响度:指一个常见故障危害范畴乘于常见故障危害时间的总数。这儿用常见故障影响度来表明常见故障总的伤害水平,记为 F(r)。
风险性期待:指每一个风险性变常见故障的几率乘于每一个风险性变常见故障后的常见故障影响度的总数。这儿用风险性期待来表明风险性的潜在性伤害水平,记为 E(r)。
风险性期待的公式计算
依据以前的界定,能够计算出风险性期待的公式计算以下:
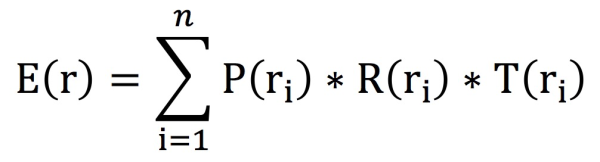
r 意味着风险性,风险性期待会伴随着风险性的总数 n 和每一个风险性的 P、R、T 降低而降低,通称 nPRT 公式计算。(注:假如要引入该公式计算请标明出處。)
操纵风险性的 4 大要素(nPRT)
①降低风险性总数,n
从根源避开风险性,保证与风险性媒介无联接,无关联;那麼该风险性几率就是0,都不关注该风险性产生后的常见故障影响度是大是小,彻底不关注。
比如:重特大节日主题活动,实施整站封网,变动的总数便会获得一个显著的降低,便是典型性的降低风险性总数。
比如:系统软件 A 彻底不依靠 Oracle,那系统软件 A 就无需关注 Oracle 的一切风险性,就算特朗普总统忽然应急公布 Oracle 马上马上严禁在我国应用,系统软件 A 也不在乎。
比如:近期新冠大流行,人传承很恐怖,假如你今日挑选休假不出门,那么你今日就不必担心被外边的路人与同事感染。
②减少风险性变常见故障的几率(即:提升风险性变常见故障的难度系数),P
把风险性当做一个目标对待,给它逐层设卡,提升风险性变常见故障的门坎和难度系数,不要让“一不小心多了一个空格符或标识符,系统软件就挂掉”这类血案随便发生。
比如:工作人员 B 要系统对 C 进行变更,能够对工作人员 B 提升变动认证考试,对变动內容规定线下推广(或模拟仿真)检测,对变动內容开展 CR,系统软件 C 出示变动实际效果浏览工作能力(相近监管方式或试运转)。
万一工作人员 B 想故意变动捣乱,还能够提升非同人核查,系统软件C能够提升防呆设计方案开展维护这些。
比如:以新冠为例子,带口罩,讲究卫生,多自然通风等就可以减少沾染新冠的几率。
③减少常见故障危害范畴,R
以大拆小,将一个总体拆分为 N 个小的个人,每一个个人中间开展互相防护,单独个人出难题仅危害单独个人,完成小而精。
比如:分布式架构就是这个的楷模,集中型一损俱损,分布式系统一损即 N 分之一损。
比如:以新冠为例子,综合治理,各省市或市间的流动性开展限定,跨地区务必核苷酸 防护 14 天,合理操纵新冠的散播范畴。
④减少常见故障危害时间,T
常见故障危害时间由常见故障发觉時间和常见故障止血時间决策,因此 要早发现早止血。
发觉方法分成:事先的预警信息,过后的报警。尽量朝事先预警信息去做,给止血转变态度乃至将风险性抹杀在摇蓝中。
止血方法分成:转换,回退,扩充,退级 or 过流保护,BUG 修补等。常见故障发生时第一优先选择标准为快速止血(如转换、回退、扩充),禁止去精准定位根因;当没法快速止血时以少出血为第二优先选择标准,如退级、过流保护。
止血高效率:全自动 vs 人力 ;一键化 vs 多步实际操作。尽量用自动化技术去替代人力实际操作,若人力实际操作时尽可能完成一键化,提高止血速率。
比如:针对容积水位线,能够在警界线以前划一条平仓线,提早预警信息,坦然面对。
比如:分布式架构群集,一切一台网站服务器有什么问题时,web服务会根据心率查验全自动把有什么问题的网站服务器去除,将要求发送给别的(热)备份数据沉余的网络服务器上。
比如:以新冠为例子,但因为每一个性命全是独一无二的,没有办法转换,也没有办法回退,也不可以退级(涉及到人道主义精神),只有对症治疗渐渐地医治。
高可用性架构模式的 7 大关键标准
依据 nPRT 公式计算,在高可用性架构模式时有下列 7 个关键标准:
①少依靠标准:能不依靠的,尽量不依靠,越低越高(n)
因为全部事情都并不是 100% 靠谱的,当 2 个事情中间拥有关联,那麼便会互相影响,就相互之间另一方的一个风险性,一个出难题很有可能会危害此外一个。大家统一用依靠来特指这里的“关联”。
比如:一个系统软件另外依靠 Oracle,MySQL,OB 三种关联型数据库查询,少依靠标准是改为仅依靠最完善平稳的 OB,不依靠 Oracle 和 MySQL。
哪些情景合适多依靠?当引进依靠(n 增大)能够减少 PRT 中的一个或好几个,且使 E(r) 总体降低。
比如:为处理 DB 风险性,引进分布式缓存,只需 2 者不另外挂的情况下仍然能用。
②弱依靠标准:一定要依靠的,尽量弱依靠,越弱越好(P)
事情 a 强依靠事情 b,一旦 b 出难题时,那麼 a 也会出难题,一损俱损。因此 一切强依靠都需要尽量的转换成弱依靠,能够立即减少出难题的几率。
比如:买卖关键链接在成功交易后要给客户派发積分利益;买卖关键系统软件必须依靠積分利益系统软件,好的方法是选用弱依靠,应用多线程化的方法,那样積分利益系统软件不能用时,大概率不容易危害买卖关键链接。
③分散化标准:生鸡蛋不必放一个竹篮,分散化风险性(R)

打撒拆分为 N 份;防止全局性仅有 1 份,不然一有什么问题危害范畴便是 100%。
比如:全部买卖数据信息都放到同一个库同一张表里边,万一这一库挂掉,这时危害全部买卖。
比如:将自身全部的钱买来同一只股票,万一这只个股是乐视电视就惨了。
④平衡标准:匀称分散化风险性,防止不平衡(R)

最好是 N 份中的每一份全是平衡的;防止某一市场份额过大,不然过大的这份一有什么问题就危害范畴过变大。
比如:xx 运用群集有 1000 台,但因为引流方法部件 Bug,造成 全部总流量引到在其中 100 台上边,造成 负荷比较严重不平衡,最终因负荷没法背着全方位奔溃。相近重特大常见故障早已发生了数次。
比如:将自身全部的钱买来 10 只个股,在其中一只占有率 99%,万一这只个股是乐视电视就惨了。
⑤防护标准:操纵风险性不外扩散,不变大(R)
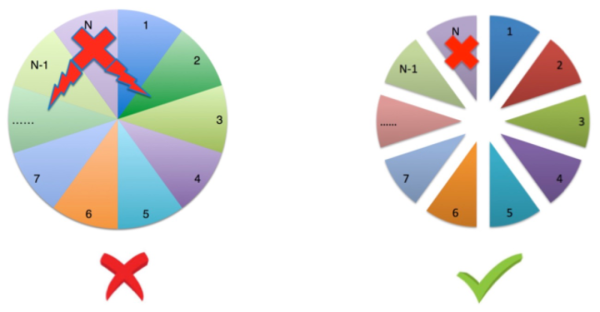
每一份中间是互相防护的;防止一份有什么问题危害别的的也有什么问题,散播外扩散了危害范畴。
比如:买卖数据信息拆分为 10 库 100 表,可是布署在同一台物理学机里;万一某张表有一条大 SQL 把网口打满了,那 10 库 100 表都是会受影响。
比如:将自身全部的钱平均分买来 10 只个股,每只都占 10%,但 10 只全是乐视电视系的。
比如:古时候赤壁大战便是一个典型性的背面事例,挂锁连船造成 防护性被毁坏,一把大火烧了 80w 精兵。
防护是有等级的,隔离级别越高,风险性散播外扩散的难度系数就越大,容灾备份工作能力越强。
比如:一个运用群集由 N 台网络服务器构成,布署在同一台物理学机里,或同一个主机房的不一样物理学机里,或同一个大城市的不一样主机房里,或不一样大城市里,不一样的布署意味着不一样的容灾备份工作能力。
比如:人们由成千上万人构成,日常生活在同一个地球的不一样洲上,这代表着人们不具有星体等级的防护工作能力,当地球上发生破坏性危害时,人们不是具有容灾备份的。
防护标准是一个至关重要的标准,它是前边 4 个标准的前提条件。
沒有搞好防护,前边 4 个标准全是敏感的,风险性非常容易散播外扩散开,毁坏前边 4 个标准的实际效果。
很多真正系统异常是由于防护性做得不太好造成 的,如:线下推广危害网上,线下危害线上,预发危害生产制造,一条烂 SQL 危害全部库(或全部群集)这些。
分散化,平衡,防护是操纵风险性危害范畴的 3 个关键标准。打撒拆分为 N 份,每一份全是平衡的,且互相防护,一份有什么问题,危害范畴为 1/N。
⑥无点射标准:要有沉余或别的版本号,保证有山能退(T)
快速止血的方法是转换,回退,扩充等;回退和扩充归属于独特的转换,回退指的是转换到某一版本号,扩充指的是将总流量转换到新扩充的设备上。
转换得有地区能切才行,因此 不可以有点射(这儿专指强依靠的点射,弱依靠的能够退级),要有服务器集群或别的版本号;点射会限定总体的稳定性。
假定点射的稳定性假定是 99.99%,它要提高到 99.999% 是十分艰难的,可是假如无点射只是依靠 2 个(1 个挂了没有关系,只需不另外挂就可以了),那总体稳定性便是 99.999999% 会出现质的提高。
服务器宕机会造成 没法快速止血,变长全部止血時间,去点射尤为重要。这儿的点射不仅指的是系统软件连接点,也包括工作人员,如定阅报警的人,紧急的人这些。
针对(关键)数据信息连接点,务必达到无点射标准,不然极端化状况下很有可能导致数据信息永久性遗失,始终没法修复;(关键)数据信息连接点达到无点射标准后,确保数据信息一致性比易用性规定更关键。
比如:一个商户仅适用一个付款方式,便是典型性的点射,万一这一付款方式挂掉就不可以付款了。
比如:一个家中的全部收益仅依靠爸爸一个的薪酬收益,万一这一爸爸生病了,就沒有收益了。
无点射标准和分散化标准的差别:
⑦防范意识标准:少出血,放弃一部分,维护此外一部分(P&R&T)
外界的键入都并不是 100% 靠谱的,有时是不经意的不正确,有时乃至是故意的毁坏,因而对于外界键入要有防呆设计方案,为自己多一些维护。
极端化状况下很有可能没法(迅速)止血,能够考虑到少出血,放弃一部分维护此外一部分。比如:过流保护,退级等。
比如:大促最高值期内,一般会提早退级掉许多 作用,另外过流保护,主要是为了更好地维护最高值绝大多数人的买卖付款感受。
比如:身体在失血过多或痛疼过多时便会开启心搏骤停状况,这也是一种典型性的防范意识体制。
手机软件风险性在何方
前边详细介绍了操纵风险性的方式,返回系统软件这一行业,它的风险性又在哪儿?
以系统软件为目标,从内看包含:测算系统软件和分布式存储;由外看包含:工作人员,硬件配置,上下游系统软件,中下游系统软件;及其(暗含的)時间。
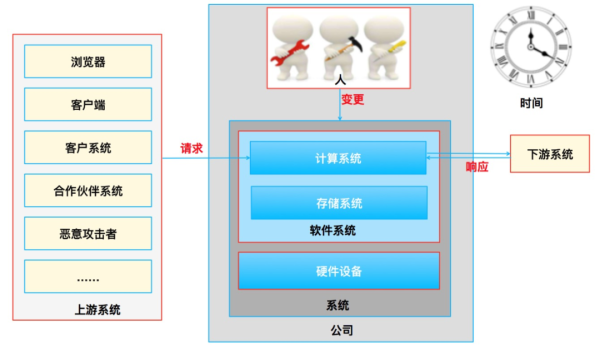
因为每一个目标全是由别的目标构成的,因而每一个目标还能够再次往细溶解(理论上能够无尽溶解下来),上边的溶解方法主要是为了更好地简单化了解。
系统软件风险性的来源于
风险性来源于(有伤害的)转变,一个目标的风险性来自全部跟它有关系的目标的(有伤害的)转变。
因而,系统软件风险性的来源于,分成下列 7 大类:
①测算系统软件转变:运作减缓,运行错误
系统软件运作所依靠的服务器空间(如 CPU,MEM,IO 等),运用資源(RPC 线程数,DB 线程数等),业务流程資源(业务流程 ID 满了,余额不足,业务流程信用额度不足等)的负荷等都是会危害系统软件运作的风险性期待。
②分布式存储转变:运作减缓,运行错误,数据信息不正确
系统软件运作所依靠的服务器空间(如 CPU,MEM,IO 等),服务器资源(并发数等),公共数据(单库容,单表容积等)的负荷和数据信息一致性等都是会危害分布式存储运作的风险性期待。
③人的转变:变动打错
变动工作人员的总数,生产安全观念,掌握情况,变动的总数,变动的方法等都是会危害变动的风险性期待。
因为变动的人多,变动的频次也多,造成 变动变成小蚂蚁全部常见故障来源于里的 TOP1,这也是为什么“变动三板斧”那么知名的缘故。
“变动三板斧”恰当的排列应该是“可灰度,可监管,可紧急”;可灰度意味着的是 R,可监管和可紧急意味着的是 T。
思索:假如变动三板斧使你再加一大斧,你觉得应当是啥?
④硬件配置转变:毁坏
硬件配置的总数,品质,使用年限,维护保养等都是会危害硬件配置的风险性期待,硬件配置毁坏会危害顶层系统软件不能用。
⑤上下游转变:要求增大
要求分成 3 个层面:(由成千上万 API 汇聚而成的)数据流量,(由成千上万 KEY 要求构成的)API,KEY。
因此 大促确保的情况下,不仅是关心关键 API 的容积确保,还必须考虑到数据流量和网络热点 KEY。
⑥中下游转变:回应减缓,回应不正确
中下游服务项目的总数,服务项目级别,服务项目能用率等危害中下游服务项目的风险性期待。中下游回应减缓很有可能会拖慢上下游,中下游回应不正确很有可能会危害上下游运作結果。
⑦時间转变:時间期满
時间期满通常被别人忽略,但它通常具备忽然和全局性毁灭性,一旦時间期满开启常见故障会造成 十分处于被动,因此 要提早鉴别,尽快预警信息,如:密匙期满,资格证书期满,花费期满,跨时区时间,跨年夜,跨月,跨日等。
比如:2019 年日本营运商软银投资因资格证书期满引起 3000w 客户长达 4 钟头通讯终断。
之上每一大类风险性都能够根据 nPRT 公式计算开展逐一剖析解决。
风险性的总数:一生三,三生万物
一切一个事情既是由别的事情构成的也是别的事情的构成部分,不断循环下来;一生三,三生万物,风险性的总数是数不胜数的。
向内看,含有内,能够无限小下来;当分子粒度分布的难题散播开落,也很有可能危害系统软件的易用性,如同 100 纳米技术的新冠病毒就可以危害身体的易用性一样。
向外看,外有外,能够无穷大下来;当太阳系行星摧毁,系统软件的易用性当然就荡然无存。
尽管风险性数不胜数,可是只需大家对风险性多一些掌握,依据操纵风险性的一些核心理念和标准,還是能够更强的减少风险性期待。
谈一谈心存敬畏:
结语
小结以下:
创作者:乐羊
编写:陶家龙
出處:转载微信公众号阿里技术(ID:ali_tech)






