

照片来源于 Pexels
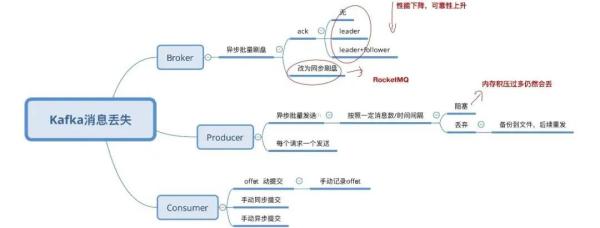
Broker
Broker
遗失信息是因为 Kafka 自身的缘故导致的,Kafka 为了更好地获得高些的特性和货运量,将数据信息多线程大批量的储存在硬盘中。
信息的地刷全过程,为了更好地提升特性,降低地刷频次,Kafka 选用了大批量地刷的作法。即,依照一定的信息量,和间隔时间开展地刷。
这类体制也是因为 Linux 电脑操作系统决策的。将数据储存到 Linux 电脑操作系统种,会先储存到页缓存文件(Page cache)中,依照時间或是别的标准开展地刷(从 Page Cache 到 file),或是根据 fsync 指令强制性地刷。
数据信息在Page Cache里时,假如系统软件挂了,数据信息会遗失。
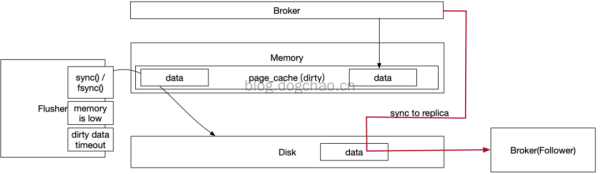
Broker 在 Linux 网络服务器高速读写能力及其同歩到 Replica
图中概述了 Broker 写数据信息及其同歩的一个全过程。Broker 写数据信息只提到 Page Cache 中,而 Page Cache 坐落于运行内存。
这些数据信息在关闭电源后是会遗失的。Page Cache 的数据信息根据 Linux 的 flusher 程序流程开展地刷。
地刷开启标准有三:
Broker 配备地刷体制,是根据启用 fsync 涵数对接了地刷姿势。从单独 Broker 看来,Page Cache 的数据信息会遗失。
Kafka 沒有出示同歩地刷的方法。同歩地刷在 RocketMQ 中有完成,完成基本原理是将多线程地刷的步骤开展堵塞,等候回应,相近 Ajax 的 callback 或是是 Java 的 future。
下边是一段 RocketMQ 的源代码:
- GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() result.getWroteBytes());
- service.putRequest(request);
- boolean flushOK = request.waitForFlush(this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout()); // 地刷
换句话说,理论上,要彻底让 Kafka 确保单独 Broker 不遗失信息是做不到的,只有根据调节地刷体制的主要参数减轻该状况。
例如,降低地刷间距,降低地刷信息量尺寸。時间越少,特性越差,稳定性越好(尽量靠谱)。这是一个单选题。
为了更好地处理该难题,Kafka 根据 Producer 和 Broker 协作解决单独 Broker 遗失主要参数的状况。
一旦 Producer 发觉 Broker 信息遗失,就可以全自动开展 retry。除非是 retry 频次超出阀值(可配备),信息才会遗失。
这时必须经营者手机客户端手动式解决该状况。那麼 Producer 是怎样检验到内容丢失的呢?是根据 ack 体制,类似 http 的三次握手的方法。
The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent. The following settings are allowed:
acks=0 If set to zero then the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and the retries configuration will not take effect (as the client won’t generally know of any failures). The offset given back for each record will always be set to -1.
acks=1 This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost.
acks=allThis means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting.
http://kafka.apache.org/20/documentation.html
之上的引入是 Kafka 官方网针对主要参数 acks 的表述(在老版本中,该主要参数是 request.required.acks):
①acks=0,Producer 不等候 Broker 的回应,高效率最大,可是信息很可能会丢。
②acks=1,leader broker 接到信息后,不等候别的 follower 的回应,即回到 ack。还可以了解为 ack 数为 1。
这时,假如 follower 都还没接到 leader 同歩的信息 leader 就挂掉,那麼信息会遗失。
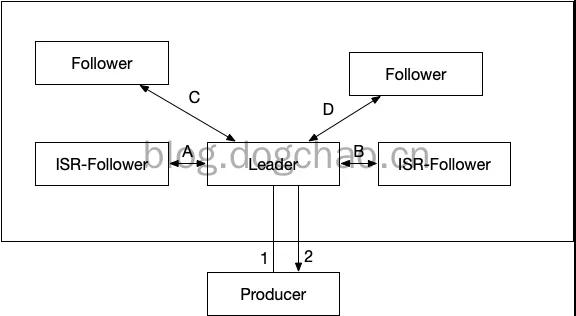
依照图中中的事例,假如 leader 接到信息,取得成功载入 PageCache 后,会回到 ack,这时 Producer 觉得信息发送成功。
但这时,依照图中,数据信息都还没被同歩到 follower。假如这时 leader 关闭电源,数据信息会遗失。
③acks=-1,leader broker 接到信息后,脱机,等候全部 ISR 目录中的 follower 回到結果后,再回到 ack。
-1 等效电路与 all。这类配备下,仅有 leader 载入数据信息到 pagecache 是不容易回到 ack 的,还必须全部的 ISR 回到“取得成功”才会开启 ack。
假如这时关闭电源,Producer 能够了解信息沒有被发送成功,可能再次推送。假如在 follower 接到数据信息之后,取得成功回到 ack,leader 关闭电源,数据信息将存有于原先的 follower 中。在再次大选之后,新的 leader 会拥有该一部分数据信息。
数据信息从 leader 同歩到 follower,必须 2 步:
上边第三点提及了 ISR 的目录的 follower,必须相互配合另一个主要参数才可以更强的确保 ack 的实效性。
ISR 是 Broker 维护保养的一个“靠谱的 follower 目录”,in-sync Replica 目录,Broker 的配备包括一个主要参数:min.insync.replicas。
该主要参数表明 ISR 中至少的团本数。如果不设定该值,ISR 中的 follower 目录很有可能为空。这时等同于 acks=1。
如圖中:
特性先后下降,稳定性先后上升。
Producer
Producer遗失信息,产生在经营者手机客户端。
为了更好地提高高效率,降低 IO,Producer 在传送数据时能够将好几个要求开展合拼后推送。被合拼的要求咋推送一线缓存文件在当地 buffer 中。
缓存文件的方法和上文提及的地刷相近,Producer 能够将要求装包成“块”或是依照间隔时间,将 buffer 中的数据信息传出。
根据 buffer 我们可以将经营者更新改造为多线程的方法,而这能够提高大家的推送高效率。
可是,buffer 中的数据信息便是风险的。在一切正常状况下,手机客户端的异步调用能够根据 callback 来解决信息推送不成功或是请求超时的状况。
可是,一旦 Producer 被不法的终止了,那麼 buffer 中的数据信息将遗失,Broker 将没法接到该一部分数据信息。
又或是,当 Producer 手机客户端存储空间不足时,假如采用的对策是丢掉信息(另一种对策是 block 堵塞),信息也会被遗失。
亦或,信息造成(多线程造成)过快,造成 脱机进程太多,内存不够,造成 程序流程奔溃,信息遗失。
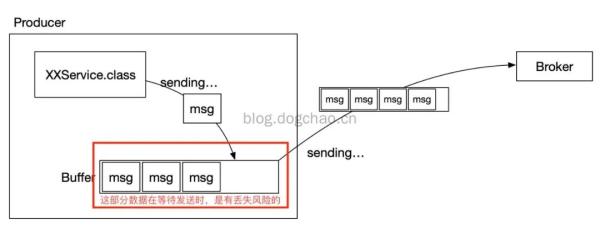
Producer 采用大批量推送的平面图
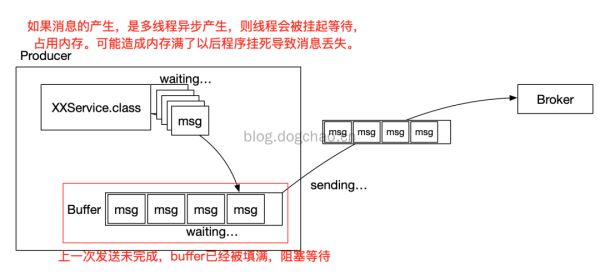
多线程推送信息生产制造速率过快的平面图
依据图中,能够想起好多个处理的构思:
Consumer
Consumer 消費信息有下边好多个流程:
Consumer的消费方式关键分成二种:
Consumer 全自动递交的体制是依据一定的间隔时间,将接到的信息开展 commit。commit 全过程和消費信息的全过程是多线程的。
换句话说,很有可能存有消費全过程未取得成功(例如抛出异常),commit 信息早已递交了。这时信息就遗失了。
- Properties props = new Properties();
- props.put("bootstrap.servers", "localhost:9092");
- props.put("group.id", "test");
- // 全自动递交电源开关
- props.put("enable.auto.commit", "true");
- // 全自动递交的时间间距,这里是1s
- props.put("auto.commit.interval.ms", "1000");
- props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
- props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
- KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
- consumer.subscribe(Arrays.asList("foo", "bar"));
- while (true) {
- // 启用poll后,100ms后,信息情况会被改成 committed
- ConsumerRecords<String, String> records = consumer.poll(100);
- for (ConsumerRecord<String, String> record : records)
- insertIntoDB(record); // 将信息进库,時间很有可能会超出100ms
上边的实例是全自动递交的事例。假如这时,insertIntoDB(record) 产生出现异常,信息可能发生遗失。
下面是手动式递交的事例:
- Properties props = new Properties();
- props.put("bootstrap.servers", "localhost:9092");
- props.put("group.id", "test");
- // 关掉全自动递交,改成手动式递交
- props.put("enable.auto.commit", "false");
- props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
- props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
- KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
- consumer.subscribe(Arrays.asList("foo", "bar"));
- final int minBatchSize = 200;
- List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
- while (true) {
- // 启用poll后,不容易开展auto commit
- ConsumerRecords<String, String> records = consumer.poll(100);
- for (ConsumerRecord<String, String> record : records) {
- buffer.add(record);
- }
- if (buffer.size() >= minBatchSize) {
- insertIntoDb(buffer);
- // 全部信息消費结束之后,才开展commit实际操作
- consumer.commitSync();
- buffer.clear();
- }
将递交种类改成手动式之后,能够确保信息“最少被消費一次”(at least once)。但这时很有可能发生反复消費的状况,反复消費不属于这篇探讨范畴。
上边2个事例,是立即应用 Consumer 的 High level API,手机客户端针对 offset 等操纵是全透明的。
还可以选用 Low level API 的方法,手动式操纵 offset,还可以确保信息不丢,但是会更为繁杂。
- try {
- while(running) {
- ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
- for (TopicPartition partition : records.partitions()) {
- List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
- for (ConsumerRecord<String, String> record : partitionRecords) {
- System.out.println(record.offset() ": " record.value());
- }
- long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
- // 精准操纵offset
- consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset 1)));
- }
- }
- } finally {
- consumer.close();
- }
创作者:DongGuoChao
编写:陶家龙
出處:https://blog.dogchao.cn/?p=305






