

文中转载微信公众平台「苏三说技术性」,创作者因为热爱因此 坚持不懈ing。转截文中请联络苏三说技术性微信公众号。
序言
我的卖家企业是做餐饮系统的,每日下午和夜里就餐高峰时段,系统软件的并发量不可小觑。为了更好地保险起见,企业要求各单位都需要在用餐的時间轮流值班,避免出现网上难题时可以妥善处理。
我那时候在餐厅厨房显示设备精英团队,该系统软件归属于订单信息的中下游业务流程。客户点完菜提交订单后,订单管理系统会根据发kafka信息给大家系统软件,系统软件载入信息后,做领域模型解决,持久化订单信息和菜肴数据信息,随后展现到划菜手机客户端。那样主厨就了解哪一个订单信息要做什么菜,有一些菜搞好了,就可以根据该系统软件出餐。系统软件全自动通告服务生上餐,假如服务生上完菜,改动菜肴上餐情况,客户就了解什么菜早已到了,什么都还没上。这一系统软件能够进一步提高餐厅厨房到客户的高效率。
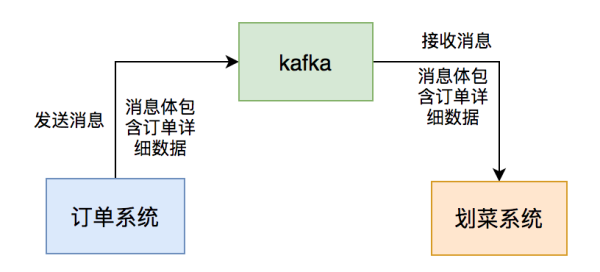
事实上,这一切的关键是消息中间件:kafka,假如它有什么问题,可能立即危害到餐厅厨房显示设备的作用。
下面,我跟大伙儿一起聊聊应用kafka2年時间踩过什么坑?
次序难题
1. 为何要确保信息的次序?
一开始大家系统软件的商户非常少,为了更好地迅速完成作用,大家没想的太多。即然是走消息中间件kafka通讯,订单管理系统发信息时将订单信息详尽数据信息放到信息体,大家餐厅厨房显示设备只需定阅topic,就能获得有关信息数据信息,随后解决自身的业务流程就可以。
但是这套计划方案有一个首要条件:要确保信息的次序。
为什么呢?
订单信息有很多情况,例如:提交订单、付款、进行、撤消等,不太可能提交订单的信息都没载入到,就先载入付款或撤消的信息吧,假如确实那样,数据信息并不是会造成紊乱?
行吧,来看确保信息次序是必须的。
2.怎样确保信息次序?
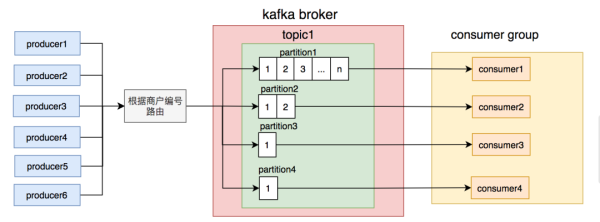
大家都了解kafka的topic是混乱的,可是一个topic包括好几个partition,每一个partition內部是井然有序的。
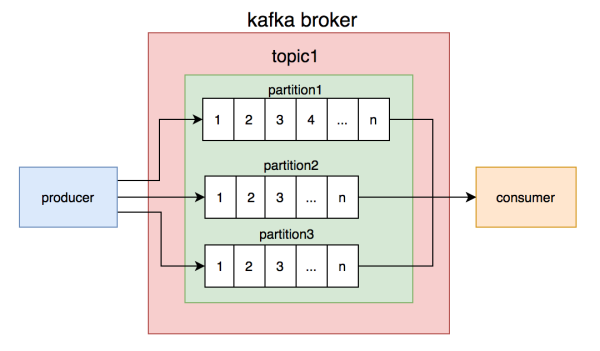
如此一来,构思就越来越清楚了:只需确保经营者写信息时,依照一定的标准写到同一个partition,不一样的顾客读不一样的partition的信息,就能确保生产制造和顾客信息的次序。
大家一开始便是那么做的,同一个商户编号的信息写到同一个partition,topic中建立了4个partition,随后布署了4个顾客连接点,组成顾客组,一个partition相匹配一个顾客连接点。从理论上说,这套计划方案是可以确保信息次序的。

一切整体规划得看起来“无懈可击”,大家就是这样”成功“上线。
3.发生意外
该作用上线一段时间,一开始還是较为一切正常的。
可是,好景不常,迅速就接到客户举报,说在划菜手机客户端有一些订单信息和菜肴一直看不见,没法划菜。
我精准定位到缘故,企业在哪一段时间互联网常常不稳定,业务流程插口隔三差五报请求超时,业务流程要求隔三差五会连不上数据库查询。
这类状况对次序信息的严厉打击,能够说成破坏性的。
为何那么说?
假定订单管理系统发过:”提交订单“、”付款“、”进行“ 三条信息。

而”提交订单“信息因为互联网缘故大家系统软件解决失败了,而后边的两根信息的数据信息是没法进库的,由于仅有”提交订单“信息的数据信息才算是详细的数据信息,其他类型的信息总是升级情况。
再加上,大家那时候沒有做不成功再试体制,促使这个问题被变大了。难题变为:一旦”提交订单“信息的数据信息进库不成功,客户就始终看不见这一订单信息和菜肴了。
那麼这一应急的难题要如何解决呢?
4.处理全过程
最初大家的念头是:在顾客解决信息时,假如解决失败了,立刻再试3-5次。但假如有一些要求要第六次才可以取得成功该怎么办?不太可能一直再试呀,这类同歩再试体制,会堵塞别的商户订单信息信息的载入。
显而易见用上边的这类同歩再试体制在发现异常的状况,会比较严重危害信息顾客的消費速率,减少它的货运量。
这般来看,大家迫不得已用多线程再试体制了。
假如用多线程再试体制,解决不成功的信息就得储存到重试表出来。
但有一个新难题立刻发生:只存一条信息怎样确保次序?
存一条信息确实没法确保次序,倘若:”提交订单“信息失败了,还不等他多线程再试。这时,”付款“信息被消費了,它肯定是不可以被一切正常消費的。
这时,”付款“信息该一直等待,每过一段时间分辨一次,它前边的信息都是否有被消費?
假如确实那么做,会发生2个难题:
这时候有一种更简易的计划方案露出水面:顾客在解决信息时,先分辨该订单编号在重试表是否有数据信息,如果有则立即把当今信息储存到重试表。要是没有,则开展业务流程解决,假如发现异常,把该信息储存到重试表。
之后大家用elastic-job创建了不成功再试体制,假如再试了7次能還是不成功,则将该信息的情况标识为不成功,发送邮件通告开发者。
总算因为网络不好,导致用户在划菜手机客户端有一些订单信息和菜肴一直看不见的难题被解决了。如今商户最多有时候延迟时间见到菜肴,比一直看不菜肴好过多。
信息库存积压
伴随着营销团队的品牌推广,大家系统软件的商户愈来愈多。接踵而来的是信息的总数越来越大,造成 顾客解决不回来,经常会出现信息库存积压的状况。对商户的危害十分形象化,划菜手机客户端上的订单信息和菜肴很有可能半小时后才可以见到。一两分钟还能忍,一个半信息的延迟时间,对有一些爆脾气的商户哪儿忍得了,立刻举报过来了。大家那一段时间常常收到商户举报说订单信息和菜肴有延迟时间。
虽然,加服务器节点就能解决困难,可是依照企业为了更好地划算的国际惯例,要先做优化系统,因此 大家开始了信息库存积压解决问题之行。
1. 信息体过大
虽然kafka称为适用上百万级的TPS,但从producer推送信息到broker必须一次互联网IO,broker写数据信息到硬盘必须一次硬盘IO(写实际操作),consumer从broker获得信息先历经一次硬盘IO(读实际操作),再历经一次互联网IO。
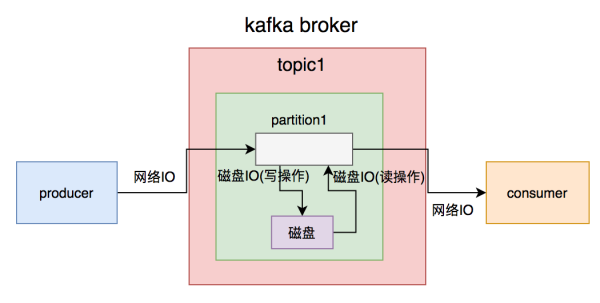
一次简易的信息从生产制造到消費全过程,必须历经2次互联网IO和2次硬盘IO。假如信息体过大,必定会提升IO的用时,从而危害kafka生产制造和消費的速率。顾客速率很慢的結果,便会发生信息库存积压状况。
除开上边的难题以外,信息体过大,还会继续消耗网络服务器的储存空间,稍不留意,很有可能会发生储存空间不够的状况。
这时,大家早已到必须提升信息体过问题的情况下。
怎样提升呢?
大家再次整理了一下业务流程,沒有必需了解订单信息的中间状态,只需了解一个最后情况就可以了。
如此甚好,大家就可以那样设计方案了:
订单管理系统推送的信息体仅用包括:id和情况等重要信息内容。
餐厅厨房显示设备消費信息后,根据id启用订单管理系统的订单信息查看插口读取数据。
餐厅厨房显示设备分辨数据库查询中是不是有该订单信息的数据信息,要是没有则进库,有则升级。
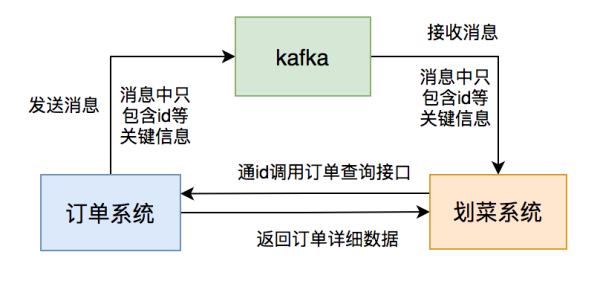
果真那样调节以后,信息库存积压难题较长一段时间都没再发生。
2. 路由器标准不科学
还真别开心的过早,有一天下午又有商户举报说订单信息和菜肴有延迟时间。我们一查kafka的topic居然又发生了信息库存积压。
但此次有点儿怪异,非是全部partition上的信息都是有库存积压,只是只有一个。
一开始,原以为是消費那一个partition信息的连接点出了什么问题造成 的。可是历经清查,沒有发觉一切出现异常。
这就怪异了,究竟哪有难题呢?
之后,我搜日志和数据库查询发觉,几个商户的订单信息量尤其大,恰好这好多个商户被分得同一个partition,促使该partition的信息成交量放大别的partition要多许多。
这时候大家才意识到,发信息时按商户编号路由器partition的标准不科学,很有可能会造成 有一些partition信息过多,顾客解决不回来,而有一些partition却由于信息太少,顾客发生空余的状况。
为了更好地防止出现这类分派不匀称的状况,大家必须对发信息的路由器标准做一下调节。
大家思索了一下,用订单编号做路由器相对性更匀称,不容易发生单独订单信息发信息频次尤其多的状况。除非是是碰到某一人一直放肉的状况,可是放肉是必须掏钱的,因此 实际上同一个订单信息的信息总数并不是很多。
调节后按订单编号路由器到不一样的partition,同一个订单编号的信息,每一次到发至同一个partition。
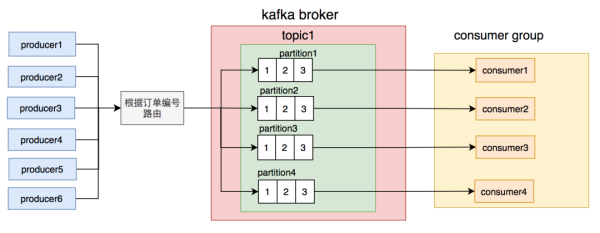
调节后,信息库存积压的难题又有较长一段时间也没有再发生。大家的商户总数在这段时间,提高的十分快,愈来愈多了。
3. 批量操作造成的链式反应
在分布式系统的情景中,信息库存积压难题,可以说如影随行,确实没法从源头上处理。表层上看,早已解决了,但后边不清楚何时,便会出现一次,例如此次:
有一天中午,商品回来说:几个商户举报过来了,有人说菜肴有延迟时间,快查一下缘故。
此次难题发生得有点儿怪异。
为何那么说?
最先这一时间点就有点儿怪异,平时出难题,不全是下午或是夜里就餐高峰时段吗?如何此次难题发生在下午?
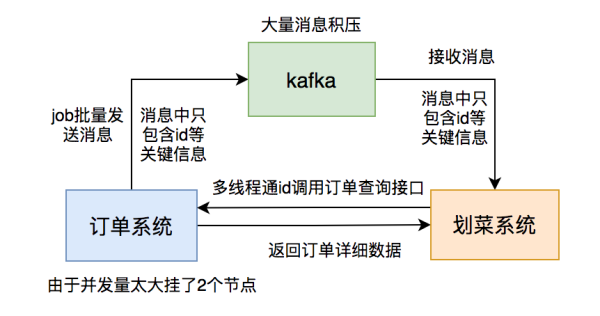
依据过去累积的工作经验,我立即看过kafka的topic的数据信息,果真上边信息有库存积压,但此次每一个partition都库存积压了十几万的信息沒有消費,比过去充压的信息总数提升了十几倍。此次信息库存积压得极不寻常。
我赶快查服务项目监管看一下顾客挂掉没,还行没挂。又查服务项目日志沒有出现异常。这时候我有点儿茫然,看运气问了问订单信息组中午发生什么事事儿没?有人说中午有一个营销活动,跑了一个JOB批量更新过有一些商户的订单信息。
这时候,我一下子恍然大悟,是她们在JOB中大批量发信息造成 的难题。怎么没有通告大家呢?真是太坑了。
虽然了解难题的缘故了,倒是眼下库存积压的这十几万的信息该如何处理呢?
这时,假如立即调大partition总数是不好的,历史时间信息早已储存到4个固定不动的partition,仅有增加的信息才会到新的partition。大家关键必须解决的是现有的partition。
立即加服务项目连接点也不好,由于kafka容许一个组的好几个partition被一个consumer消費,但不允许一个partition被一个组的好几个consumer消費,很有可能会导致資源消耗。
来看仅有用线程同步解决了。
为了更好地应急解决困难,我改为了用线程池解决信息,关键进程和较大 线程数都配备变成50。
调节以后,果真,信息库存积压总数持续降低。
但这时有一个更比较严重的难题发生:我收到了警报电子邮件,有两个订单管理系统的连接点down机了。
没多久,订单信息组的朋友回来找我讲,大家系统进程她们订单号查询插口的并发量猛增,超出了预估的数倍,造成 有两个服务项目连接点挂掉。她们把查看作用独立变成了一个服务项目,布署了6个连接点,挂掉两个连接点,再不解决,此外4个连接点也会挂。订单信息服务项目能够说成企业最关键的服务项目,它挂掉企业损害会非常大,状况十分应急。
为了更好地处理这个问题,只有先把线程数调小。
幸亏,线程数是能够根据zookeeper动态性调节的,我将关键线程数调变成八个,关键线程数改为了10个。
后边,运维管理把订单信息服务项目挂的两个连接点重新启动后恢复过来了,以防万一,再加多了两个连接点。为了更好地保证订单信息服务项目不容易发生难题,就维持现阶段的消費速率,餐厅厨房显示设备的信息库存积压难题,1小情况下后也恢复过来了。
之后,大家开过一次总结会,得到的结果是:
顺带说一下,针对规定严苛确保信息次序的情景,能够将线程池改为好几个序列,每一个序列用并行处理解决。
4. 表过大
为了更好地避免后边再次发生信息库存积压难题,顾客后边就一直用线程同步解决信息。
但有一天下午大家還是接到许多警报电子邮件,提示大家kafka的topic信息有库存积压。大家已经查缘故,这时商品冲过来说:又有商户举报说菜肴有延迟时间,赶快看一下。此次她看上去有一些厌烦,的确提升了很数次,還是发生了一样的难题。
在非专业来看:为何同一个难题一直难以解决?
实际上技术性内心的苦她们是不清楚的。
表层上难题的病症是一样的,全是发生了菜肴延迟时间,她们了解的是由于信息库存积压造成 的。可是她们不清楚多方面的缘故,造成 信息库存积压的缘故实际上有很多种多样。这或许是应用消息中间件的常见问题吧。
我默不作声,只有咬着牙精准定位缘故了。
之后我搜日志发觉顾客消費一条信息的用时将近2秒。之前是500ms,如今为什么会变为2秒呢?
怪异了,顾客的编码都没有做大的调节,怎么会发生这类状况呢?
查了一下网上菜肴表,单表信息量居然到上千万,别的的划菜表也是一样,如今单表储存的数据信息太多了。
大家组整理了一下业务流程,实际上菜肴在手机客户端只展现近期三天的就可以。
这就找邦企了,大家服务器端存着不必要的数据信息,比不上把表格中不必要的数据信息存档。因此,DBA帮大家把数据信息干了存档,只保存近期7天的数据信息。
这般调节后,信息库存积压难题被解决了,又修复了往日的宁静。
主键矛盾
别激动得过早了,也有别的的难题,例如:警报电子邮件常常给出数据库查询出现异常: Duplicate entry '6' for key 'PRIMARY',说主键矛盾。
发生这类难题一般是因为有两个之上同样主键的sql,另外插进数据信息,第一个插进取得成功后,第二个插进的情况下会报主键矛盾。表的主键是唯一的,不允许反复。
我认真仔细了编码,发觉编码逻辑性会先依据主键从表格中查订单是不是存有,假如存有则升级情况,不会有才插进数据信息,没有难题。
这类分辨在并发量并不大时,是有效的。可是假如在分布式系统的情景下,2个要求同一時刻都查出订单信息不会有,一个要求先插进数据信息,另一个要求再插进数据信息时便会发生主键矛盾的出现异常。
处理这个问题最基本的作法是:上锁。
我一开始也是那样想的,加数据库查询悲观锁肯定是不好的,太危害特性。加数据库查询乐观锁,根据版本信息分辨,一般用以升级实际操作,像这类插进实际操作大部分不容易用。
剩余的只有用分布式锁了,大家系统软件再用redis,能够加根据redis的分布式锁,锁住订单编号。
但后边细心思索了一下:
因此 ,我也不准备用分布式锁。
只是挑选应用mysql的INSERT INTO ...ON DUPLICATE KEY UPDATE英语的语法:
- INSERT INTO table (column_list)
- VALUES (value_list)
- ON DUPLICATE KEY UPDATE
- c1 = v1,
- c2 = v2,
- ...;
它会先试着把数据信息插进表,假如主键矛盾得话那麼升级字段名。
把之前的insert句子更新改造以后,就没再发生过主键矛盾难题。
数据库查询主从关系延迟时间
没多久以后的某一天,又接到商户举报说提交订单后,在划菜手机客户端上看获得订单信息,可是见到的菜肴不全,有时候乃至订单信息和菜肴数据信息都看不见。
这个问题跟过去的都不一样,依据过去的工作经验首先看kafka的topic中信息是否有库存积压,但此次并沒有库存积压。
再查了服务项目日志,发觉订单管理系统插口回到的数据信息有一些为空,有一些只回到了订单信息数据信息,没回到菜肴数据信息。
这就十分怪异了,我立即以往找订单信息组的朋友。她们细心清查服务项目,沒有发现问题。这时候大家不谋而合的想起,是否会是数据库查询出难题了,一起去找DBA。果真,DBA发觉数据库查询的主库同歩数据信息到从库,因为互联网缘故有时候有延迟时间,有时候延迟时间有3秒。
如果我们的工作流程从发信息到消費信息用时低于3秒,启用订单信息查看插口时,很有可能会查不出数据信息,或是查出的并不是全新的数据信息。
这个问题十分比较严重,会造成 立即大家的数据信息不正确。
为了更好地处理这个问题,大家也加了再试体制。启用插口查看数据信息时,假如回到数据信息为空,或是只回到了订单信息沒有菜肴,则添加重试表。
调节后,商户举报的难题被解决了。
反复消費
kafka消費信息时适用三种方式:
kafka默认设置的方式是at least onece,但这类方式很有可能会造成反复消費的难题,因此 大家的领域模型务必做幂等设计方案。
而大家的业务场景储存数据信息时应用了INSERT INTO ...ON DUPLICATE KEY UPDATE英语的语法,不会有时插进,存有时升级,是纯天然适用幂等性的。
多自然环境消費难题
大家那时候网上自然环境分成:pre(预公布自然环境) 和 prod(工作环境),2个自然环境同用同一个数据库查询,而且同用同一个kafka群集。
必须留意的是,在配备kafka的topic的情况下,要加前缀用以区别不一样自然环境。pre自然环境的以pre_开始,例如:pre_order,工作环境以prod_开始,例如:prod_order,避免信息在不一样自然环境中串了。
但有一次运维管理在pre自然环境转换连接点,配备topic的情况下,配不对,配出了prod的topic。恰好那一天,大家有新作用上pre自然环境。結果悲剧了,prod的有一些信息被pre自然环境的consumer消費了,而因为信息体干了调节,造成 pre自然环境的consumer解决信息一直不成功。
其結果是工作环境丟了一部分信息。但是还行,最终工作环境顾客根据重设offset,再次载入了那一部分信息解决了难题,沒有导致很大损害。
续篇
除开所述难题以外,我都遇到过:
这两个难题说起来有一些繁杂,我不一一列举了,有兴趣爱好的盆友能够关注我的微信公众号,加我的手机微信找我聊私信。
特别感谢那2年应用消息中间件kafka的历经,虽然遇到过挺多难题,踩了许多坑,离开了许多弯道,可是实实在在的要我累积了许多珍贵的工作经验,迅速发展了。
实际上kafka是一个十分出色的消息中间件,我所碰到的绝大部分难题,都并不是kafka本身的难题(除开cpu使用率100%是它的一个bug造成 的以外)。





