

文中转载微信公众平台「虞胆大的唧唧喳喳」,创作者虞胆大 。转截文中请联络虞胆大的唧唧喳喳微信公众号。
构建数仓,hadoop尽管有点儿过时,但或是必不可少的。文中叙述下单机的hadoop运行体制。
HDFS是Google GFS的开源系统完成,是一个分布式存储,是云计算技术的根基,立即上框架图:
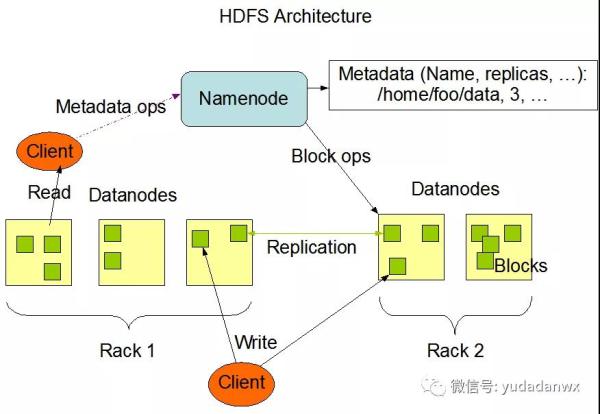
关键包括Namenode和Datanodes,MapReduce关键便是在Datanodes开展并行处理。
core-site.xml:
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost:8001</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/root/hadoop-3.2.2/tmp</value>
- </property>
在其中8001端口号就意味着hdfs的根途径,此外hdfs-site.xml配备主要参数也十分多。
例如dfs.replication表明hdfs团本集,单机就设定1;dfs.namenode.http-address是NameNode web管理方法详细地址,能够查询hdfs的一些状况;dfs.datanode.address是DataNode的端口号;dfs.namenode.name.dir和dfs.namenode.data.dir表明Namenode和Datanodes的储存文件目录,默认设置承继于hadoop.tmp.dir值。
假如改动文件目录有关的主要参数,必须 恢复出厂设置hdfs:
- $ bin/hdfs namenode -format
工作经验便是提议删掉dfs.namenode.data.dir下的文档,再恢复出厂设置。
一旦hdfs可以用,实际操作他们如同实际操作本地文件一样:
- #建立登录客户的网站根目录,拥有网站根目录,则不用特定hdfs://作为前缀
- $ ./bin/hdfs dfs -mkdir -p "hdfs://localhost:8001/user/root"
- $ ./bin/hdfs dfs -mkdir -p test2
- $ ./bin/hdfs dfs -put ~/test.log hdfs://localhost:8001/test
- $ ./bin/hdfs dfs -put ~/test.log test2
- $ ./bin/hdfs dfs -ls test2
- $ ./bin/hdfs dfs -cat test2/test.log
接下来说说MapReduce,关键包括map和reduce全过程,此外不能忘记shuffle,map相对性于从hdfs dataNodes解决数据信息,随后shuffle将关联的数据信息交到reduce开展解决。
运作MapReduce全过程非常简单:
- $ bin/hdfs dfs -mkdir input
- $ bin/hdfs dfs -put etc/hadoop/*.xml input
- # 将mapreduce每日任务实行的結果放进 hdfs output 文件目录中
- $ bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.] '
- bin/hdfs dfs -cat output/*
初期的MapReduce即包括测算架构,又包括生产调度架构,较为松垮,例如想在当今群集运作此外一种测算每日任务,也不便捷了,因此之后从MapReduce里将生产调度架构提取出去,取名为Yarn,那样无论是MapReduce或是Spark只需合乎Yarn接口标准,就能被Yarn生产调度,MR和Spark专做一做分布式系统计算,等同于解耦了。
Yarn的框架图以下:
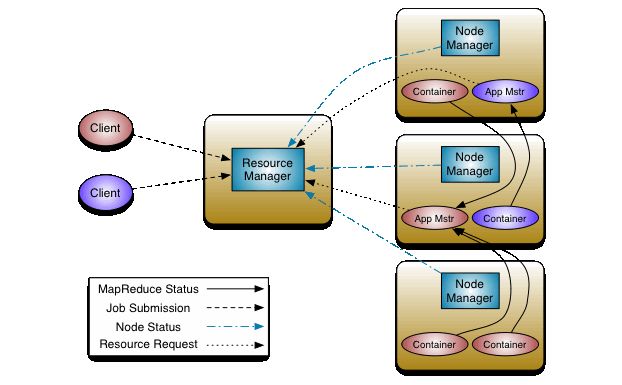
关键包含ResourceManager和NodeManager,此外为了更好地分布式系统计算NodeManager一般和HDFS的DataNodes运作在一起。
ResourceManager关键包括Scheduler和ApplicationsManager。
改动yarn-site.xml:
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.resourcemanager.webapp.address</name>
- <value>0.0.0.0:7088</value>
- </property>
在其中,mapreduce_shuffle表明生产调度MapReduce每日任务,7088 是Yarn的Web管理方法详细地址;自然Yarn也有许多的主要参数。
改动 mapred-site.xml:
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
mapreduce.framework.name的值yarn表明MapReduce应用Yarn生产调度。
随后实行yarn生产调度:
- $ bin/yarn jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.] '
仅仅将上边的hadoop改动为yarn,但是結果检测,不管怎么写,yarn全是起效的,根据yarn Web UI可以看出去。
此外我是以root运作的,因此sbin下的一些sh文件要改动:
- HDFS_DATANODE_USER=root
- HDFS_DATANODE_SECURE_USER=root
- HDFS_NAMENODE_USER=root
- HDFS_SECONDARYNAMENODE_USER=root
最终的启动命令:
- $ ./sbin/start-all.sh
- $ ./sbin/stop-all.sh
参照连接:
https://kontext.tech/column/hadoop/265/default-ports-used-by-hadoop-services-hdfs-mapreduce-yarn
https://hadoop.apache.org/docs/r3.2.2/hadoop-project-dist/hadoop-common/SingleCluster.html





