
近期,confluent小区发布了一篇文章,关键叙述了Kafka将来的2.8版本号即将舍弃Zookeeper,这针对Kafka客户而言,是一个关键的改善。以前布署Kafka就务必得布署Zookeeper,而以后就只需独立布署Kafka就可以了。[1]
Apache Kafka最开始是由Linkedin企业开发设计,之后捐赠给了Apack慈善基金会。
Kafka被官方网界定为分布式系统流式的解决服务平台,由于具有高吞吐、可分布式锁、可水准拓展等特点而被普遍应用。现阶段Kafka实际以下作用:
下边这幅图是Kafka的信息实体模型:[2]
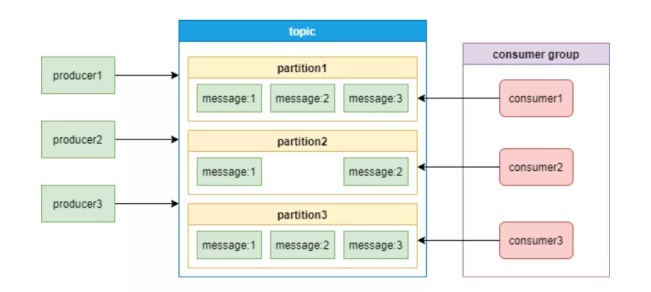
根据上边这幅图,介绍一下Kafka中的好多个关键定义:
Kafka构架如下图:
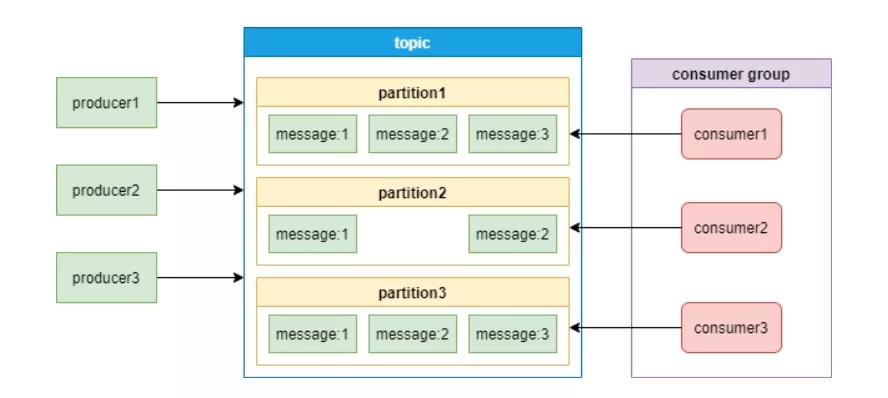
从图上能够见到,Kafka的工作中必须 Zookeeper的相互配合。那她们到底是如何配合工作呢?
看下面这幅图:

从上边的图上能够见到,broker分布式部署,就必须 一个认证中心来开展统一管理方法。Zookeeper用一个专业连接点储存Broker服务项目目录,也就是 /brokers/ids。
broker在运作时,向Zookeeper推送申请注册要求,Zookeeper会在/brokers/ids下建立这一broker连接点,如/brokers/ids/[0...N],并储存broker的IP地址和端口号。
这一连接点临时性连接点,一旦broker服务器宕机,这一临时性连接点会被全自动删掉。
Zookeeper也会为topic分派一个独立连接点,每一个topic都是会以/brokers/topics/[topic_name]的方式纪录在Zookeeper。
一个topic的信息会被储存到好几个partition,这种partition跟broker的对应关系也必须 储存到Zookeeper。
partition是多团本储存的,图中中色partition是leader团本。当leader团本所属的broker产生常见故障时,partition必须 再次大选leader,这一必须 由Zookeeper核心进行。
broker运行后,会把自己的Broker ID申请注册到相匹配topic连接点的系统分区目录中。
大家查询一个topic是xxx,系统分区序号是1的信息内容,指令以下:
- [root@master] get /brokers/topics/xxx/partitions/1/state
- {"controller_epoch":15,"leader":11,"version":1,"leader_epoch":2,"isr":[11,12,13]}
当broker撤出后,Zookeeper会升级其相匹配topic的系统分区目录。
顾客组也会向Zookeeper开展申请注册,Zookeeper会为其分派连接点来储存有关数据信息,连接点途径为/consumers/{group_id},有3个子连接点,如下图:

那样Zookeeper能够纪录系统分区跟顾客的关联,及其系统分区的offset。[3]
broker向Zookeeper开展申请注册后,经营者依据broker连接点来认知broker服务项目目录转变,那样能够完成动态性web服务。
consumer group中的顾客,能够依据topic连接点信息内容来获取特殊系统分区的信息,完成web服务。
事实上,Kafka在Zookeeper中储存的数据库十分多,看下面这幅图:
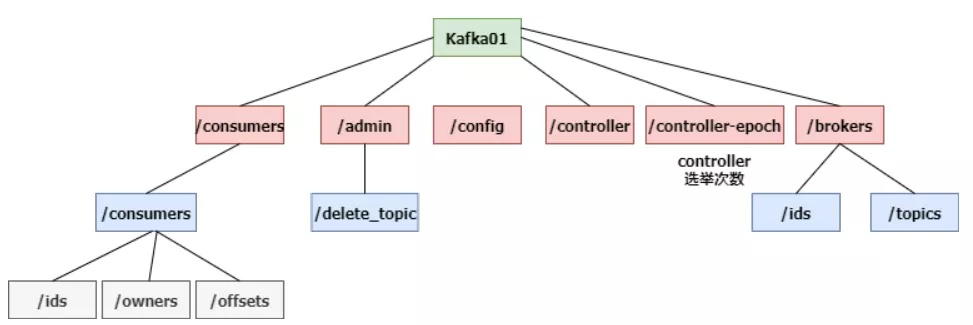
伴随着broker、topic和partition增加,储存的信息量会越来越大。
历经上一节的叙述,大家看到了Kafka对Zookeeper的依靠十分大,Kafka离去Zookeeper是没有办法单独运作的。那Kafka是怎么跟Zookeeper开展互动的呢?
如下图:[4]
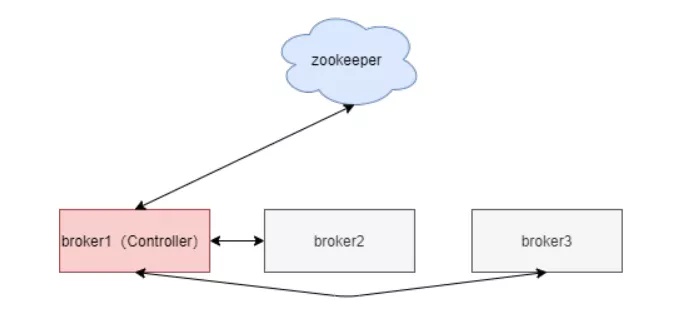
Kafka群集中会有一个broker被大选为Controller承担跟Zookeeper开展互动,它部门管理全部Kafka群集中全部系统分区和团本的情况。别的broker监视Controller连接点的数据信息转变。
Controller的大选工作中取决于Zookeeper,大选取得成功后,Zookeeper会建立一个/controller临时性连接点。
Controller实际岗位职责以下:
监视系统分区转变
例如当某一系统分区的leader发生常见故障时,Controller会为该系统分区大选新的leader。当检验到系统分区的ISR结合产生变化时,Controller会通告所有broker升级数据库。当某一topic提升系统分区时,Controller会承担分配系统分区。
下边这幅图展现了Controller、Zookeeper和broker的互动关键点:
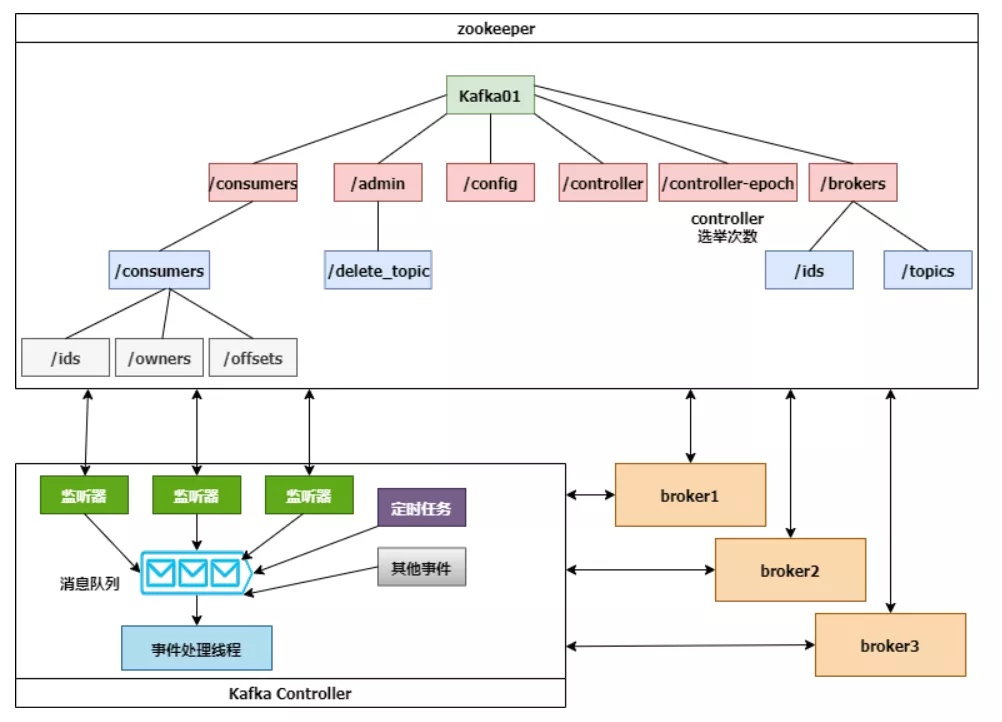
Controller大选取得成功后,会从Zookeeper群集中拉取一份详细的数据库复位ControllerContext,这种数据库缓存文件在Controller连接点。当群集产生变化时,例如提升topic系统分区,Controller不但必须 变动当地的缓存文件,还必须 将这种变动信息内容同歩到别的Broker。
Controller监视到Zookeeper事情、计划任务事情和别的事情后,将这种事情依照顺序储存到LinkedBlockingQueue中,由事故处理进程按序解决,这种解决大部分必须 跟Zookeeper互动,Controller则必须 升级自身的数据库。
Kafka自身便是一个分布式架构,可是必须 另一个分布式架构来管理方法,多元性毫无疑问提升了。
应用了Zookeeper,布署Kafka的情况下务必要布署两个系统软件,Kafka的运维管理工作人员务必要具有Zookeeper的运维管理工作能力。
Kafka依靠一个单一Controller连接点跟Zookeeper开展互动,假如这一Controller连接点发生了常见故障,就必须 从broker中挑选新的Controller。如下图,新的Controller变成了broker3。
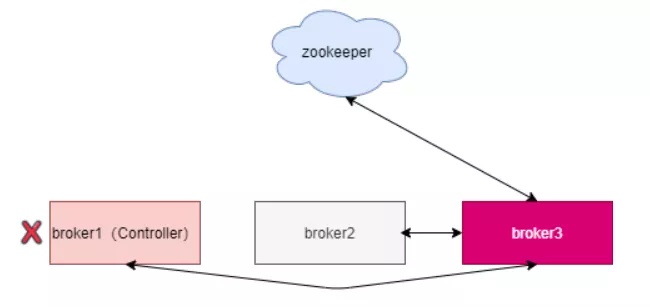
新的Controller大选取得成功后,会再次从Zookeeper获取数据库开展复位,而且必须 通告别的全部的broker升级ActiveControllerId。老的Controller必须 关掉监视、事故处理进程和计划任务。系统分区数十分多时,这一全过程十分用时,并且这一全过程中Kafka群集是不可以工作中的。
当系统分区数提升时,Zookeeper储存的数据库变多,Zookeeper群集工作压力增大,做到一定等级后,监视延迟时间提升,给Kafka的工作中产生了危害。
因此,Kafka单群集安装的系统分区总数是一个短板。而这又刚好是一些业务场景必须 的。
升級前后左右的框架图比照以下:
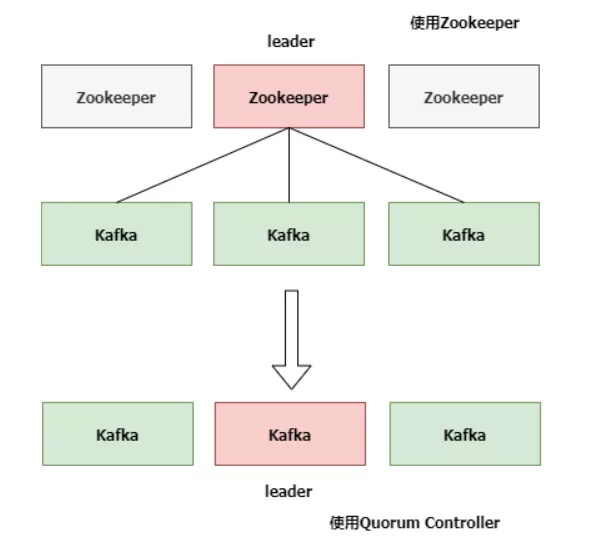
KIP-500用Quorum Controller替代以前的Controller,Quorum中每一个Controller连接点都是会储存全部数据库,根据KRaft协议书确保团本的一致性。那样即便Quorum Controller连接点出常见故障了,新的Controller转移也会十分快。
官方网详细介绍,升級以后,Kafka能够轻轻松松适用上百万等级的系统分区。
Kafak团队把根据Raft协议书同歩数据信息的方法Kafka Raft Metadata mode,通称KRaft
Kafka的客户规模十分大,在不断服的状况下升級是必需的。
现阶段除去Zookeeper的Kafka编码KIP-500早已递交到trunk支系,而且早已在的2.8版本号公布。
Kafka方案在3.0版本号会兼容Zookeeper Controller和Quorum Controller,那样客户能够开展内部测试。[5]
在规模性群集和云原生的情况下,应用Zookeeper给Kafka的运维和群集特性导致了非常大的工作压力。除去Zookeeper是大势所趋,这也合乎道法自然的构架观念。
参考文献
[1]https://www.confluent.io/blog/kafka-without-zookeeper-a-sneak-peek/
[2]https://blog.csdn.net/Zidingyi_367/article/details/110490910
[3]https://www.jianshu.com/p/a036405f989c
[4]https://honeypps.com/mq/kafka-controller-analysis/
[5]https://mp.weixin.qq.com/s/ev6NM6小时ptltQBuTaCHJCQQ
【责编:未丽燕 TEL:(010)68476606】




