

文中转载微信公众平台「云计算技术与数仓」,创作者西贝莜面村。转截文中请联络云计算技术与数仓微信公众号。
- Function (arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>]
- [<window_expression>])
Function (arg1,..., argn) 能够是下边的四类涵数:
示例数据信息
- [员工名字|单位序号|员工ID|薪水|职位种类|新员工入职時间]
- Michael|1000|100|5000|full|2014-01-29
- Will|1000|101|4000|full|2013-10-02
- Wendy|1000|101|4000|part|2014-10-02
- Steven|1000|102|6400|part|2012-11-03
- Lucy|1000|103|5500|full|2010-01-03
- Lily|1001|104|5000|part|2014-11-29
- Jess|1001|105|6000|part|2014-12-02
- Mike|1001|106|6400|part|2013-11-03
- Wei|1002|107|7000|part|2010-04-03
- Yun|1002|108|5500|full|2014-01-29
- Richard|1002|109|8000|full|2013-09-01
建表语句:
- CREATE TABLE IF NOT EXISTS employee (
- name string,
- dept_num int,
- employee_id int,
- salary int,
- type string,
- start_date date
- )
- ROW FORMAT DELIMITED
- FIELDS TERMINATED BY '|'
- STORED as TEXTFILE;
载入数据信息
- load data local inpath '/opt/datas/data/employee_contract.txt' into table employee;
(1)查看名字、单位序号、薪水及其单位总数
- select
- name,
- dept_num as deptno ,
- salary,
- count(*) over (partition by dept_num) as cnt
- from employee ;
結果輸出:
- name deptno salary cnt
- Lucy 1000 5500 5
- Steven 1000 6400 5
- Wendy 1000 4000 5
- Will 1000 4000 5
- Michael 1000 5000 5
- Mike 1001 6400 3
- Jess 1001 6000 3
- Lily 1001 5000 3
- Richard 1002 8000 3
- Yun 1002 5500 3
- Wei 1002 7000 3
(2)查看名字、单位序号、薪水及其每一个单位的总薪水,单位总薪水依照降序輸出
- select
- name ,
- dept_num as deptno,
- salary,
- sum(salary) over (partition by dept_num order by dept_num) as sum_dept_salary
- from employee
- order by sum_dept_salary desc;
結果輸出:
- name deptno salary sum_dept_salary
- Michael 1000 5000 24900
- Will 1000 4000 24900
- Wendy 1000 4000 24900
- Steven 1000 6400 24900
- Lucy 1000 5500 24900
- Wei 1002 7000 20500
- Yun 1002 5500 20500
- Richard 1002 8000 20500
- Lily 1001 5000 17400
- Jess 1001 6000 17400
- Mike 1001 6400 17400
介绍
对话框排序函数给予了数据信息的排列信息内容,例如行号和排行。在一个排序的內部将行号或是排行做为数据信息的一部分开展回到,最常见的排序函数关键包含:
row_number:依据实际的排序和排列,为每排数据信息转化成一个起始值相当于1的唯一编码序列数
rank:对组中的数据信息开展排行,假如成绩同样,则排行也同样,可是下一个成绩的排行编号会发生不持续。例如搜索条件的topN行
dense_rank:dense_rank涵数的作用与rank涵数相近,dense_rank涵数在转化成编号时是持续的,而rank涵数转化成的编号有可能不持续。当发生成绩同样时,则排行编号也同样。而下一个排行的编号与上一个排行编号是持续的。
percent_rank:排行计算方法为:(current rank - 1)/(total number of rows - 1)
ntile:将一个井然有序的数据区划为好几个桶(bucket),并为每排分派一个适度的桶数。它可用以将数据信息区划为相同的小切成片,为每一行分派该小切成片的数字序号。
(1)查看名字、单位序号、薪水、排行序号(按薪水的是多少排行)
- select
- name ,
- dept_num as dept_no ,
- salary,
- row_number() over (order by salary desc ) rnum
- from employee;
結果輸出:
- name dept_no salary rnum
- Richard 1002 8000 1
- Wei 1002 7000 2
- Mike 1001 6400 3
- Steven 1000 6400 4
- Jess 1001 6000 5
- Yun 1002 5500 6
- Lucy 1000 5500 7
- Lily 1001 5000 8
- Michael 1000 5000 9
- Wendy 1000 4000 10
- Will 1000 4000 11
(2)查看每一个单位薪水最大的两人的信息内容(名字、单位、工资)
- select
- name,
- dept_num,
- salary
- from
- (
- select name ,
- dept_num ,
- salary,
- row_number() over (partition by dept_num order by salary desc ) rnum
- from employee) t1
- where rnum <= 2;
結果輸出:
- name dept_num salary
- Steven 1000 6400
- Lucy 1000 5500
- Mike 1001 6400
- Jess 1001 6000
- Richard 1002 8000
- Wei 1002 7000
(3)查看每一个单位的职工工资排行信息内容
- select
- name ,
- dept_num as dept_no ,
- salary,row_number() over (partition by dept_num order by salary desc ) rnum
- from employee;
結果輸出:
- name dept_no salary rnum
- Steven 1000 6400 1
- Lucy 1000 5500 2
- Michael 1000 5000 3
- Wendy 1000 4000 4
- Will 1000 4000 5
- Mike 1001 6400 1
- Jess 1001 6000 2
- Lily 1001 5000 3
- Richard 1002 8000 1
- Wei 1002 7000 2
- Yun 1002 5500 3
(4)应用rank涵数开展排行
- select
- name,
- dept_num,
- salary,
- rank() over (order by salary desc) rank
- from employee;
結果輸出:
- name dept_num salary rank
- Richard 1002 8000 1
- Wei 1002 7000 2
- Mike 1001 6400 3
- Steven 1000 6400 3
- Jess 1001 6000 5
- Yun 1002 5500 6
- Lucy 1000 5500 6
- Lily 1001 5000 8
- Michael 1000 5000 8
- Wendy 1000 4000 10
- Will 1000 4000 10
(5)应用dense_rank开展排行
- select
- name,
- dept_num,
- salary,
- dense_rank() over (order by salary desc) rank
- from employee;
結果輸出:
- name dept_num salary rank
- Richard 1002 8000 1
- Wei 1002 7000 2
- Mike 1001 6400 3
- Steven 1000 6400 3
- Jess 1001 6000 4
- Yun 1002 5500 5
- Lucy 1000 5500 5
- Lily 1001 5000 6
- Michael 1000 5000 6
- Wendy 1000 4000 7
- Will 1000 4000 7
(6)应用percent_rank()开展排行
- select
- name,
- dept_num,
- salary,
- percent_rank() over (order by salary desc) rank
- from employee;
結果輸出:
- name dept_num salary rank
- Richard 1002 8000 0.0
- Wei 1002 7000 0.1
- Mike 1001 6400 0.2
- Steven 1000 6400 0.2
- Jess 1001 6000 0.4
- Yun 1002 5500 0.5
- Lucy 1000 5500 0.5
- Lily 1001 5000 0.7
- Michael 1000 5000 0.7
- Wendy 1000 4000 0.9
- Will 1000 4000 0.9
(7)应用ntile开展数据信息分块排行
- SELECT
- name,
- dept_num as deptno,
- salary,
- ntile(4) OVER(ORDER BY salary desc) as ntile
- FROM employee;
結果輸出:
- name deptno salary ntile
- Richard 1002 8000 1
- Wei 1002 7000 1
- Mike 1001 6400 1
- Steven 1000 6400 2
- Jess 1001 6000 2
- Yun 1002 5500 2
- Lucy 1000 5500 3
- Lily 1001 5000 3
- Michael 1000 5000 3
- Wendy 1000 4000 4
- Will 1000 4000 4
从 Hive v2.1.0逐渐, 适用在OVER句子里应用集聚涵数,例如
- SELECT
- dept_num,
- row_number() OVER (PARTITION BY dept_num ORDER BY sum(salary)) as rk
- FROM employee
- GROUP BY dept_num;
結果輸出:
- dept_num rk
- 1000 1
- 1001 1
- 1002 1
常见的剖析涵数关键包含:
假如按降序排序,则统计分析:不大于当今值的个数/总公司数(number of rows ≤ current row)/(total number of rows)。如果是降序排序,则统计分析:高于或等于当今值的个数/总公司数。例如,统计分析不大于当今薪水的总数占总人数的占比 ,用以总计统计分析。
用以统计分析对话框内往下第n行值。第一个主要参数为字段名,第二个主要参数为往下第n行(可选,默认设置为1),第三个主要参数为初始值(当往下第n个人行为NULL情况下,取初始值,如不特定,则为NULL
与lead反过来,用以统计分析对话框内往上第n行值。第一个主要参数为字段名,第二个主要参数为往上面第n行(可选,默认设置为1),第三个主要参数为初始值(当往上第n个人行为NULL情况下,取初始值,如不特定,则为NULL)
取排序内排列后,截止到当今行,最后一个值
- SELECT
- name,
- dept_num as deptno,
- salary,
- cume_dist() OVER (ORDER BY salary) as cume
- FROM employee;
結果輸出:
- name deptno salary cume
- Wendy 1000 4000 0.18181818181818182
- Will 1000 4000 0.18181818181818182
- Lily 1001 5000 0.36363636363636365
- Michael 1000 5000 0.36363636363636365
- Yun 1002 5500 0.5454545454545454
- Lucy 1000 5500 0.5454545454545454
- Jess 1001 6000 0.6363636363636364
- Mike 1001 6400 0.8181818181818182
- Steven 1000 6400 0.8181818181818182
- Wei 1002 7000 0.9090909090909091
- Richard 1002 8000 1.0
(2)统计分析高于或等于当今薪水的总数占总人数的占比
- SELECT
- name,
- dept_num as deptno,
- salary,
- cume_dist() OVER (ORDER BY salary desc) as cume
- FROM employee;
結果輸出:
- name deptno salary cume
- Richard 1002 8000 0.09090909090909091
- Wei 1002 7000 0.18181818181818182
- Mike 1001 6400 0.36363636363636365
- Steven 1000 6400 0.36363636363636365
- Jess 1001 6000 0.45454545454545453
- Yun 1002 5500 0.6363636363636364
- Lucy 1000 5500 0.6363636363636364
- Lily 1001 5000 0.8181818181818182
- Michael 1000 5000 0.8181818181818182
- Wendy 1000 4000 1.0
- Will 1000 4000 1.0
(3)依照单位统计分析不大于当今薪水的总数占单位总人数的占比
- SELECT
- name,
- dept_num as deptno,
- salary,
- cume_dist() OVER (PARTITION BY dept_num ORDER BY salary) as cume
- FROM employee;
結果輸出:
- name deptno salary cume
- Wendy 1000 4000 0.4
- Will 1000 4000 0.4
- Michael 1000 5000 0.6
- Lucy 1000 5500 0.8
- Steven 1000 6400 1.0
- Lily 1001 5000 0.3333333333333333
- Jess 1001 6000 0.6666666666666666
- Mike 1001 6400 1.0
- Yun 1002 5500 0.3333333333333333
- Wei 1002 7000 0.6666666666666666
- Richard 1002 8000 1.0
(4)按单位排序,统计分析每一个单位职工的薪水及其高于或等于该职工工资的下一个职工的薪水
- SELECT
- name,
- dept_num as deptno,
- salary,
- lead(salary,1) OVER (PARTITION BY dept_num ORDER BY salary) as lead
- FROM employee;
結果輸出:
- name deptno salary lead
- Wendy 1000 4000 4000
- Will 1000 4000 5000
- Michael 1000 5000 5500
- Lucy 1000 5500 6400
- Steven 1000 6400 NULL
- Lily 1001 5000 6000
- Jess 1001 6000 6400
- Mike 1001 6400 NULL
- Yun 1002 5500 7000
- Wei 1002 7000 8000
- Richard 1002 8000 NULL
(5)按单位排序,统计分析每一个单位职工的薪水及其不大于该职工工资的上一个职工的薪水
- SELECT
- name,
- dept_num as deptno,
- salary,
- lag(salary,1) OVER (PARTITION BY dept_num ORDER BY salary) as lead
- FROM employee;
結果輸出:
- name deptno salary lead
- Wendy 1000 4000 NULL
- Will 1000 4000 4000
- Michael 1000 5000 4000
- Lucy 1000 5500 5000
- Steven 1000 6400 5500
- Lily 1001 5000 NULL
- Jess 1001 6000 5000
- Mike 1001 6400 6000
- Yun 1002 5500 NULL
- Wei 1002 7000 5500
- Richard 1002 8000 7000
(6)按单位排序,统计分析每一个单位职工工资及其该单位最少的职工工资
- SELECT
- name,
- dept_num as deptno,
- salary,
- first_value(salary) OVER (PARTITION BY dept_num ORDER BY salary) as fval
- FROM employee;
結果輸出:
- name deptno salary fval
- Wendy 1000 4000 4000
- Will 1000 4000 4000
- Michael 1000 5000 4000
- Lucy 1000 5500 4000
- Steven 1000 6400 4000
- Lily 1001 5000 5000
- Jess 1001 6000 5000
- Mike 1001 6400 5000
- Yun 1002 5500 5500
- Wei 1002 7000 5500
- Richard 1002 8000 5500
(7)按单位排序,统计分析每一个单位职工工资及其该单位最大的职工工资
- SELECT
- name,
- dept_num as deptno,
- salary,
- last_value(salary) OVER (PARTITION BY dept_num ORDER BY salary RANGE
- BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as lval
- FROM employee;
結果輸出:
- name deptno salary lval
- Wendy 1000 4000 6400
- Will 1000 4000 6400
- Michael 1000 5000 6400
- Lucy 1000 5500 6400
- Steven 1000 6400 6400
- Lily 1001 5000 6400
- Jess 1001 6000 6400
- Mike 1001 6400 6400
- Yun 1002 5500 8000
- Wei 1002 7000 8000
- Richard 1002 8000 8000
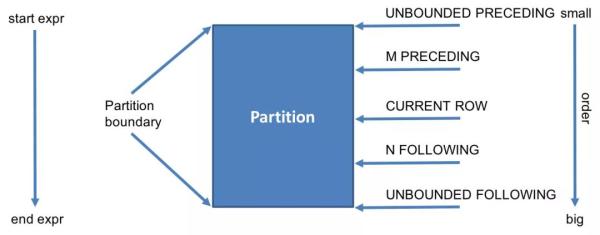
留意:last_value默认设置的对话框是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,表明当今行始终是最后一个值,需改为RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING。
img
为初始值,即当特定了ORDER BY从句,而省去了window从句 ,表明从开始到当今行。
表明从当今行至最终一行
表明全部行
表明对话框的范畴是:[(当今行的个数)- n, (当今行的个数) m]





