
创作者:ninetyhe,腾讯官方 CDG 后台开发技术工程师
学而不思则罔,不断学习培训出色的架构,定有一定的获。由于工作中缘故,必须 采用 Kafka 的独特情景,礼拜天再度阅读文章了 kafka 的材料,获得许多。
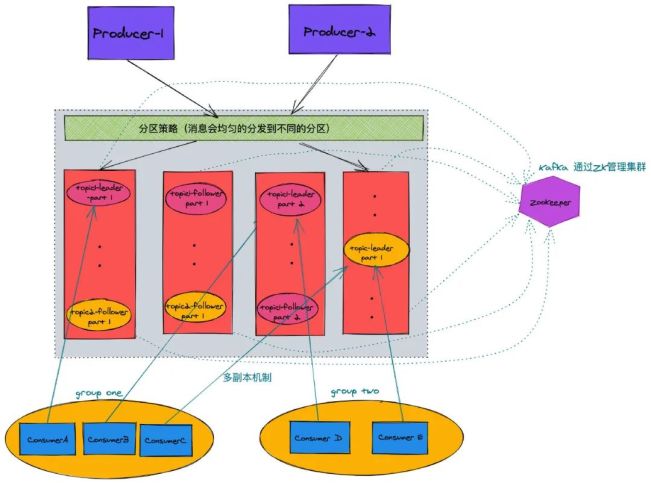
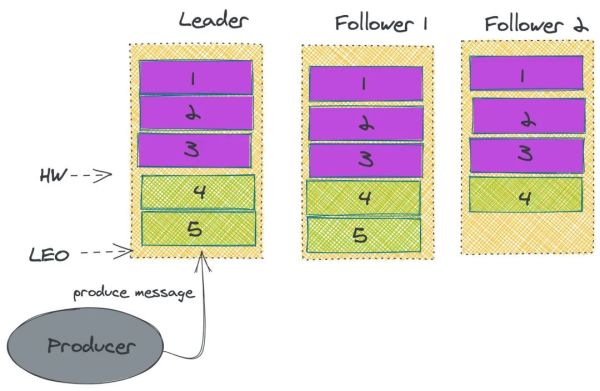
由图中我们可以发觉 Kafka 是分布式系统,与此同时针对每一个系统分区都存有多团本,与此同时全部群集的管理方法都根据 zookeeper 管理方法。
Kafka 网络服务器,承担信息储存和分享;一 broker 就意味着一个 kafka 连接点。一个 broker 能够包括好几个 topic
信息类型,Kafka 依照 topic 来归类信息

经营者,承担向 Kafka Broker 发信息的手机客户端
信息消者,承担消費 Kafka Broker 中的信息
顾客组,每一个 Consumer 务必归属于一个 group;(留意的是 一个系统分区只有由同组一个顾客消費,顾客组中间互相危害。)
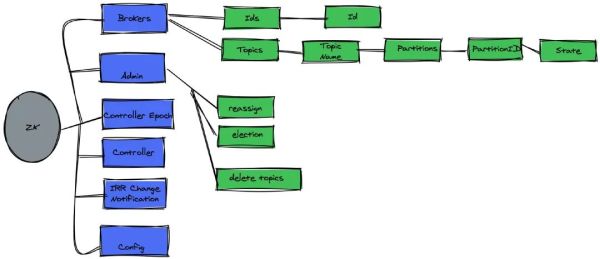
管理方法 kafka 群集,承担储存了群集 broker、topic、partition 等 meta 数据储存,与此同时也承担 broker 常见故障发觉,partition leader 大选,web服务等作用。
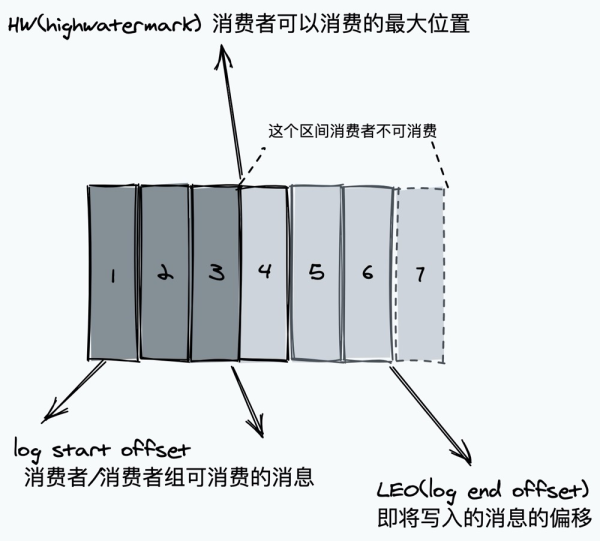
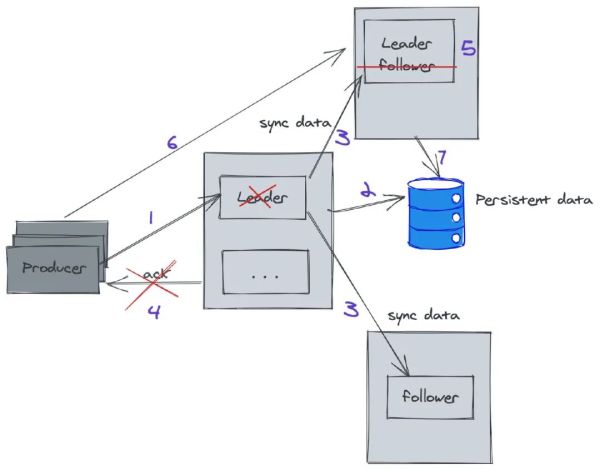
服务治理即然 Kafka 是分布式系统的公布/定阅系统软件,那样假如做的群集中间数据库同步和一致性,kafka 是否毫无疑问不容易丢信息呢?及其服务器宕机的情况下假如开展 Leader 大选呢?
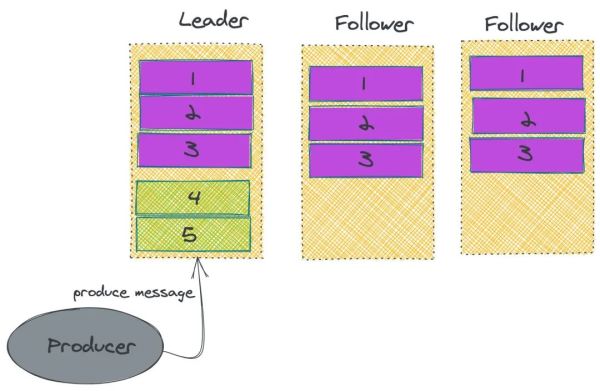
在 Kafka 中的 Partition 有一个 leader 与好几个 follower,producer 往某一 Partition 中载入数据信息是,总是往 leader 中载入数据信息,随后数据信息才会被拷贝进别的的 Replica 中。而每一个 follower 能够了解成一个顾客,按时去 leader 去拉去信息。而仅有数据库同步了后,kafka 才会给经营者回到一个 ACK 告之信息早已储存落地式了。
在 Kafka 中,为了更好地确保特性,Kafka 不容易选用强一致性的方法来同歩主从关系的数据信息。只是维护保养了一个:in-sync Replica 的目录,Leader 不用等候全部 Follower 都进行同歩,只需在 ISR 中的 Follower 进行数据库同步就可以推送 ack 给经营者就可以觉得信息同歩进行。与此同时假如发觉 ISR 里边某一个 follower 落伍过多得话,便会把它去除。
实际步骤以下:


以上的作法并没法确保 kafka 一定不丢信息。 尽管 Kafka 根据多团本体制中最大限度确保信息不容易遗失,可是假如数据信息早已载入系统软件 page cache 中可是还不等他刷入硬盘,这时忽然设备服务器宕机或是断电,那信息顺理成章的便会遗失。
Kafka 根据 Zookeeper 连坐群集的管理方法,因此这儿的大选体制选用的是 Zab(zookeeper 应用)。
Kafka 选用了次序写硬盘,而因为次序写硬盘相对性任意写,降低了寻详细地址的消耗時间。(在 Kafka 的每一个系统分区里边信息是井然有序的。
Kafka 在 OS 系统软件层面应用了 Page Cache 而不是大家平时常用的 Buffer。Page Cache 实际上不生疏,也不是哪些新事物。

我们在linux上查看内存的情况下,常常能够见到buff/cache,二者全是用于加快IO读写能力用的,而cache是功效于读,换句话说,硬盘的內容能够读到cache里边那样,应用软件读硬盘就十分快;而buff是功效于写,大家开发设计写硬盘全是,一般假如载入一个buff里边再flush就十分快。而kafka恰好是把这二者充分发挥了完美:Kafka尽管是scala写的,可是依然在Java的vm虚拟机上运作,即便如此,kafka它或是尽可能绕开了JVM的限定,它运用了Page cache来储存,那样避开了数据信息在JVM由于GC而产生的STW。另一方面也是Page Cache促使它完成了零拷贝,实际下边会讲。
不论是出色的 Netty 或是别的出色的 Java 架构,基本上都是在零拷贝降低了 CPU 的前后文转换和硬盘的 IO。自然 Kafka 都不除外。零拷贝的定义实际这儿未作太详尽的转述,大概的给大伙儿讲一下这一定义。
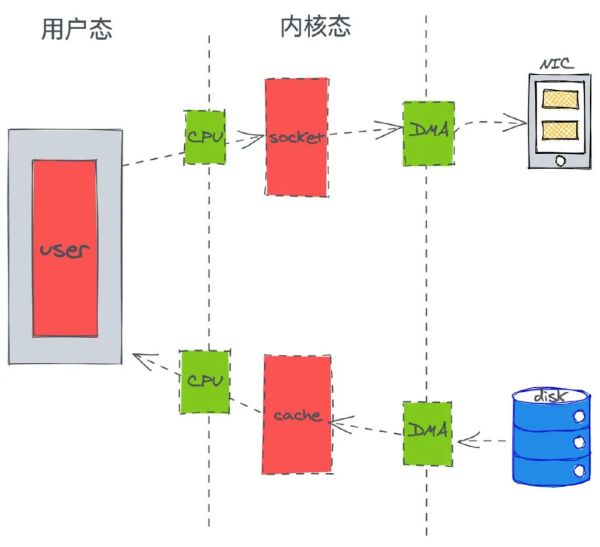
这儿大概能够发传统式的方法发生了 4 次复制,2 次 DMA 和 2 次 CPU,而 CPU 发生了 4 次的转换。_(DMA 简易了解便是,在开展 I/O 机器设备和运行内存的传输数据的情况下,数据信息运送的工作中所有交到 DMA 控制板,而 CPU 不会再参加一切与数据信息运送有关的事儿)。
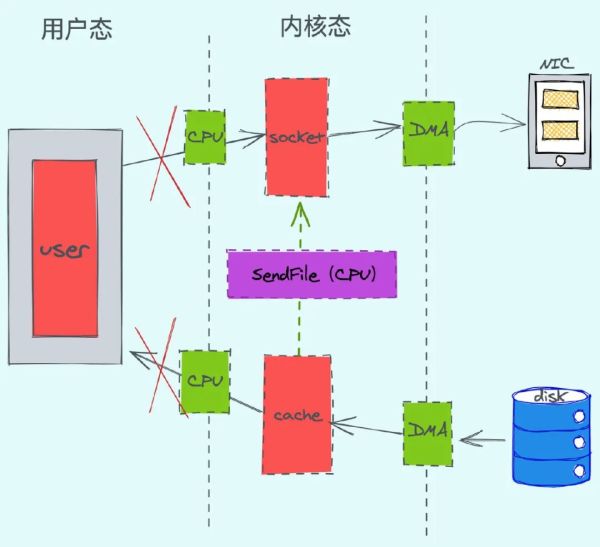
根据提升我们可以发觉,CPU 只发生了 2 次的前后文转换和 3 次数据信息复制。(linux 系统软件给予了系统软件安全事故函数调用“ sendfile()”,那样系统进程,能够立即把核心缓冲区域里的数据信息拷到 socket 缓冲区域里,不会再拷到客户态)。
大家上边也详细介绍过去了,kafka 采用了系统分区的方式,而每一个系统分区又相匹配到一个物理学按段,而搜索的情况下能够依据二分查找迅速精准定位。那样不但给予了数据信息读的查看高效率,也给予了并行操作的方法。
Kafka 对数据信息给予了:Gzip 和 Snappy 缩小协议书等缩小协议书,对信息建筑结构开展了缩小,一方面降低了网络带宽,也降低了传输数据的耗费。
因为应用压缩文件还必须 自身配备系统变量,因此这儿强烈推荐立即用 yum 安裝,了解查询现阶段 Java 的版本号:
- yum -y list Java*
安裝你要想的版本号,这儿我是 1.8
- yum install java-1.8.0-openjdk-devel.x86_64
查询是不是安裝取得成功
- Java -version
最先必须 去官方网站下载安装文件,随后缓解压力
- tar -zxvf zookeeper-3.4.9.tar.gz
要做的便是将这一文档拷贝一份,并取名为:zoo.cfg,随后在 zoo.cfg 中改动自身的配备就可以
- cp zoo_sample.cfg zoo.cfg
- vim zoo.cfg
关键配备表述以下
- # zookeeper內部的基本要素,企业是ms,这一表明一个tickTime为2000ms,在zookeeper的别的配备中,全是根据tickTime来做计算的
- tickTime=2000
- # 群集中的follower网络服务器(F)与leader网络服务器(L)中间 原始联接 时要忍受的数最多心率数(tickTime的总数)。
- initLimit=10
- #syncLimit:群集中的follower网络服务器(F)与leader网络服务器(L)中间 要求和回复 中间能忍受的数最多心率数(tickTime的总数)
- syncLimit=5
- # 数据信息储放文件夹名称,zookeeper运作全过程中有两个数据信息必须 储存,一个是快照更新数据信息(分布式锁数据信息)另一个是事务管理日志
- dataDir=/tmp/zookeeper
- ## 手机客户端浏览端口号
- clientPort=2181
配备系统变量
- vim ~/.bash_profile
- export ZK=/usr/local/src/apache-zookeeper-3.7.0-bin
- export PATH=$PATH:$ZK/bin
- export PATH
- // 运行
- zkServer.sh start
下边可以看运行取得成功

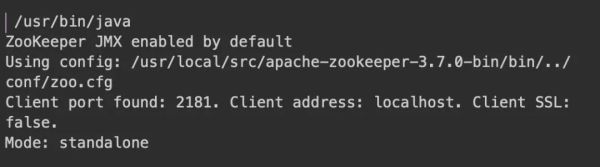
免费下载 kafka
https://www.apache.org/dyn/closer.cgi?path=/kafka/2.8.0/kafka-2.8.0-src.tgz
安裝 kafka
- tar -xzvf kafka_2.12-2.0.0.tgz
配备系统变量
- export ZK=/usr/local/src/apache-zookeeper-3.7.0-bin
- export PATH=$PATH:$ZK/bin
- export KAFKA=/usr/local/src/kafka
- export PATH=$PATH:$KAFKA/bin
运行 Kafka
- nohup kafka-server-start.sh 自身的环境变量途径/server.properties &
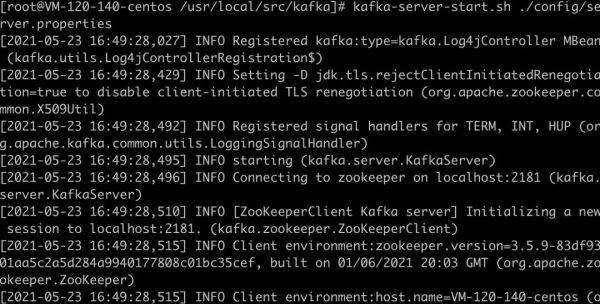
做好了!
【责编:未丽燕 TEL:(010)68476606】




