

您好,我是巡山猫!
今日大家来讲下Hive中最常见的 select from 句子专业知识关键点。
Hive系列产品文章内容预估10-20篇,关键讲数据统计分析中最基本的SQL专业技能。
查看特定的某一列或某几行,指令以下:
- SELECT 字段名1,字段名2,…… FROM 表名;
查看表格中的全部字段名时,能够应用*意味着全部字段名。星号(*)是选择全部列的快捷方式图标。指令以下:
- SELECT * FROM 表名;
如果我们想查看表 t_od_use_cnt 中的全部的user_id和use_cnt,实际指令以下:
- SELECT user_id
- ,use_cnt
- FROM app.t_od_use_cnt;
备注名称:app是数据库查询名,假如当今查看表与当今应用数据库查询一致,能够省去不写
在Hive中那样写尽管英语的语法恰当(不用系统分区),但在具体工作上那样写很可能会出错。
由于Hive中的表一般信息量巨大,为了更好地避免 客户操作失误开展全表扫描仪,能够设定为查看分区表时务必添加系统分区限定。例如这儿大家的系统分区字段名是date_8这一日期字段名,工作上的表会规定大家务必限制查看哪几天的系统分区数据信息。这儿我们可以键入设定主要参数开展仿真模拟,指令以下:
- hive (app)> set hive.mapred.mode;
- hive.mapred.mode=nonstrict
- hive (app)> set hive.mapred.mode=strict;
- hive (app)> set hive.mapred.mode;
- hive.mapred.mode=strict
随后大家再次实行上边的查看句子,出错以下:
- hive (app)> SELECT user_id
- > ,use_cnt
- > FROM app.t_od_use_cnt;
- FAILED: SemanticException [Error 10041]: No partition predicate found for Alias "t_od_use_cnt" Table "t_od_use_cnt"
- hive (app)>
以下应用where句子限制系统分区就可以处理这个问题:
- SELECT user_id
- ,use_cnt
- FROM app.t_od_use_cnt
- WHERE date_8 = '20210420';
上边的查看句子会回到查看到的全部数据信息,但有时大家仅仅要确定一下表格中的数据信息內容,或是要特定行数据信息,例如只需100行,这时候只必须在查看句子后再加上(limit 数据)就可以。
查看表t_od_use_cnt中前5行数据信息,指令以下:
- SELECT user_id
- ,use_cnt
- FROM app.t_od_use_cnt
- WHERE date_8 = 20190101 Limit 5;
运作結果以下:
- hive (app)> SELECT user_id
- > ,use_cnt
- > FROM app.t_od_use_cnt
- > WHERE date_8 = 20210420 Limit 5;
- OK
- user_id use_cnt
- 10000 6
- 10001 49
- 10002 23
- 10003 1
- 10004 29
- Time taken: 0.829 seconds, Fetched: 5 row(s)
- hive (app)>
在查看时能够对标值种类的字段名开展乘除法和取余等四则运算
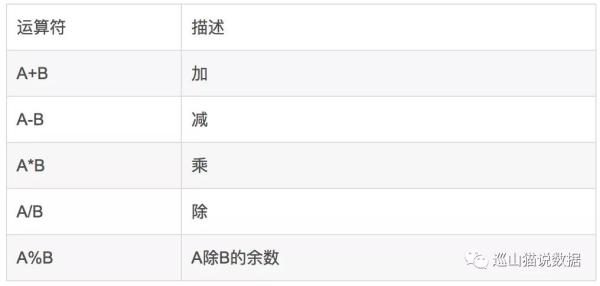
下边大家将表t_od_use_cnt中use_cnt列和is_active列乘积获得一个新列,别的使用方法依次类推。
- hive (app)> SELECT user_id
- > ,use_cnt
- > ,is_active
- > ,use_cnt * is_active
- > FROM app.t_od_use_cnt
- > WHERE date_8 = 20210420 Limit 5;
- OK
- user_id use_cnt is_active _c3
- 10000 6 1 6
- 10001 49 1 49
- 10002 23 1 23
- 10003 1 0 0
- 10004 29 1 29
- Time taken: 0.124 seconds, Fetched: 5 row(s)
- hive (app)>
能够见到上边的事例中大家根据2个列乘积人为因素生产制造出一个新列,系统软件默认设置将其字段名起为_c3。一般 必须给这种新造成的列起一个别称。现有列的字段名假如含意不清楚还可以根据起别称的方法开展变更。但是别称只在真奈美SQL句子中起效,不危害原表中的字段。
这儿顺带介绍一下字段名命名规范:
1.不可以和现有字段名反复
2.只有包含英文字母(a-z)、数据(0-9)、下横线(_)
3.以英文字母开始
4.英语单词中间用下横线_切分
这儿大家将别称起为active_use_cnt,在列后边加 AS active_use_cnt就可以。另AS能够省去,仅用空格符隔开别称还可以起效
- hive (app)> SELECT user_id
- > ,use_cnt
- > ,is_active
- > ,use_cnt * is_active AS active_use_cnt
- > FROM app.t_od_use_cnt
- > WHERE date_8 = 20210420 Limit 5;
- OK
- user_id use_cnt is_active active_use_cnt
- 10000 6 1 6
- 10001 49 1 49
- 10002 23 1 23
- 10003 1 0 0
- 10004 29 1 29
- Time taken: 0.239 seconds, Fetched: 5 row(s)
- hive (app)>





