

文中转载微信公众平台「二十二画程序猿」,创作者行小观。转截文中请联络二十二画程序猿微信公众号。
大家先讨论一下一般的二叉树有哪些缺陷。下边是一个一般二叉树(链条式储存方法):
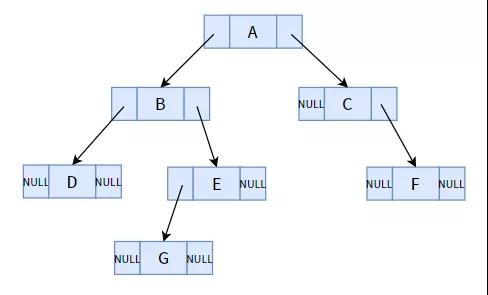
一颗一般二叉树
乍一看,是否会有一种违和?全部构造一共有 7 个节点,一共 14 个指针域,在其中却有 8 个指针域全是空的。针对一颗有 n 个节点的二叉树来讲,一共会出现 n 1 个空指针域,这一规律性应用全部的二叉树。
这么多的空指针域是否看起来很消耗?大家学习培训算法设计和优化算法的关键便是在念头想方设法地提升 時间高效率和空间利用率。这么多的指针域就那么浪费了,太败家女了!
因此 我们要想法子好好地运用他们,运用他们来协助大家能够更好地应用二叉树这一算法设计。
那麼怎样运用呢?
前边早已注重过很数次了,解析xml二叉树的本质是将二叉树中非线性结构的节点转换为线形的编码序列,随后才可以便捷大家解析xml。
例如图中的中序遍历编码序列为:DBGEACF。
针对一个线形编码序列(线性表)而言,它有立即前轮驱动和立即后续的定义(在【什么叫线性表?】中详细介绍过)。例如在中序遍历编码序列中,B 的立即前轮驱动为 D,立即后续为 G。
大家往往能了解 B 的立即前轮驱动和立即后续,是由于大家依照中序遍历的优化算法,把二叉树的中序遍历编码序列写出来,随后依据这一次序编码序列说谁的前轮驱动到底是谁、后续到底是谁。
立即前轮驱动和立即后续是不可以彻底立即根据二叉树获得的,由于二叉树中仅有父母和小孩节点中间的立即关联,即二叉树的节点指针域中只储存了其小孩节点的详细地址。
如今的要求是,我觉得能立即从二叉树上获得某节点在中序遍历方法下的立即前轮驱动和立即后续。
此刻就必须采用线索二叉树了。
自然,大家毫无疑问必须依靠节点的指针域来储存立即前轮驱动和立即后续的详细地址。
实际上,在图中的一般二叉树中(以中序遍历获得的编码序列),一部分节点(指针域不以空的节点)是能够寻找其立即前轮驱动或后续的,例如节点 E 的左小孩 G 便是节点 E 的立即前轮驱动;节点 A 的右小孩 C 便是节点 A 的立即后续。
但一部分节点(指针域为空)是难以实现的,例如节点 G 的立即后续是 E,立即前轮驱动是 B,但在二叉树中却不可以得到那样的结果。怎么办呢?大家注意到,节点 G 的2个指针域都为 NULL,仍未被运用,那麼大家应用这两个表针,各自偏向其前轮驱动和后续不就可以了嘛?
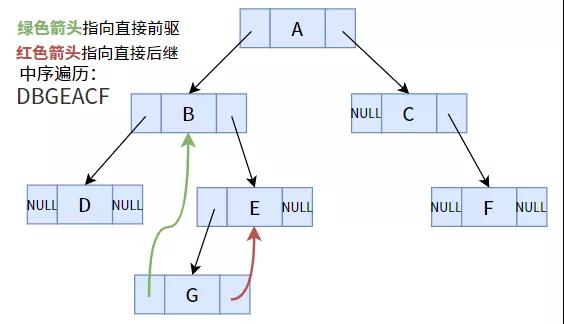
中序遍历下节点G的偏向状况
确实是十全十美,佳偶天成!可是难题并沒有处理!
由于我们都是运用空指针域来偏向前轮驱动或后续的,针对这些指针域不以空的节点,那样是分歧的,例如节点 E 和节点 B。
即然有分歧,那麼大家就发觉发生争执的根本原因,化解矛盾。
发生争执的根本原因是:节点的指针域为空和不以空时,表针的偏向分歧。即,表针不以空时偏向小孩和表针为空时偏向前轮驱动或后续中间的分歧。
那麼大家对症治疗,把指针域为空和不以空给区别出去,清楚地告知表针:不以空时偏向小孩,为空时偏向前轮驱动或后续。这就必须大家给2个表针各加上一个标志位。
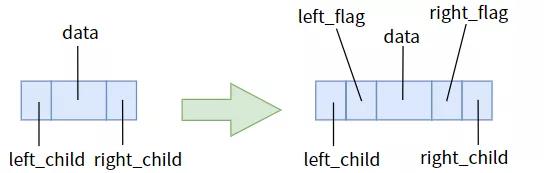
线索二叉树的节点
并承诺下列标准:
二叉树的节点要有一定的转变:
- /*线索二叉树的节点的建筑结构*/
- typedef struct Node {
- char data; //数据信息域
- struct Node *left_child; //左指针域
- int left_flag; //左表针标志位
- struct Node *right_child; //右指针域
- int right_flag; //右表针标志位
- } TTreeNode;
拥有标志位,一切就能梳理了。大家称偏向立即前轮驱动和后续的表针为案件线索。标志位为 0 的表针是偏向小孩的表针,标志位为 1 的表针是案件线索。
一个二叉链表树,节点构造如上,大家将全部空指针都变成案件线索,那样的二叉树便是二叉案件线索树。
在一般二叉树中,大家要想获得某一节点在某类解析xml顺序下的立即前轮驱动或后续,每一次都必须解析xml获得到解析xml顺序以后才可以了解。而在线索二叉树中,大家只必须解析xml一次(造就线索二叉树时的解析xml),以后,线索二叉树就能“记牢”每一个节点的立即前轮驱动和后续了,之后都不用再根据解析xml顺序获得前轮驱动或后续了。
大家依照某类解析xml方法,把一般二叉树变成线索二叉树的全过程被称作二叉树的案件线索化。
下面,大家用中序遍历的方法,将下边的二叉树案件线索化作线索二叉树
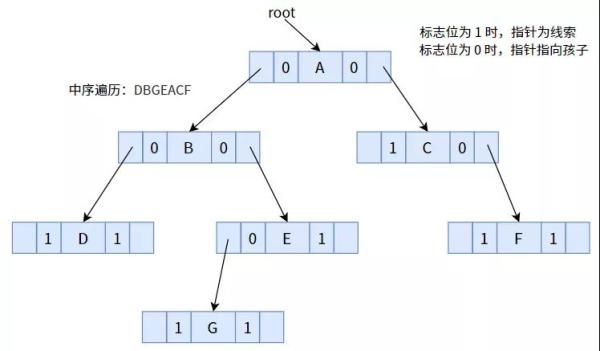
将标志位为 1 的表针,依照中序遍历编码序列,使其偏向前轮驱动或后续:
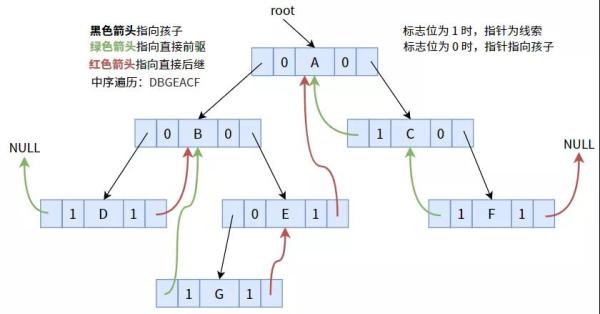
在其中,节点 D 沒有立即前轮驱动,节点 F 沒有立即后续,故表针为 NULL。
到此,大家算作解决了有着 n 个节点的二叉树存有 n 1 个空指针域所导致的消耗,处理方法是给每一个节点的表针提升一个标志位,为此来运用空指针域。标志位中储存的是 0 或 1 的布尔值,与消耗的空指针域对比,是相对性较为划得来的。并且使二叉树具备了一种新特点——二叉树里能储存在某类解析xml顺序下的节点中间的前轮驱动和后续关联。
一定要注意一点,线索二叉树是由一般二叉树获得的,并且是按某类解析xml次序获得的。由于案件线索是在了解某一节点的前轮驱动和后续的状况下才可以设定,而前轮驱动和后续关联不可以根据二叉树立即反映,只有根据解析xml二叉树获得的线形编码序列得到关联。因此 要根据某类解析xml方法获得具备前轮驱动和后续关联的编码序列后,才可以改动节点的空指针,从而设定案件线索。
即:案件线索化的本质是在依照某类解析xml顺序开展解析xml二叉树的全过程中改动节点的空指针,使其偏向其在该解析xml顺序下的立即前轮驱动或立即后续的全过程。
我们在【二叉树的遍历基本原理】和【二叉树的遍历完成】各自详细介绍了二叉树四种解析xml方法的基本原理及编码完成。那时候我们都是以打印出为例子来详细介绍解析xml的。但解析xml不仅做打印出的事,还能够做案件线索化的事。
因此 ,编码的大致构造或是一样的,大家只需把解析xml编码中的打印出编码换为案件线索化的编码,并做出一些别的更改就可以。
下边下列图为例子,各自详细介绍三种案件线索化:
一颗未案件线索化的二叉树,其全部标志位均默认设置为 0.
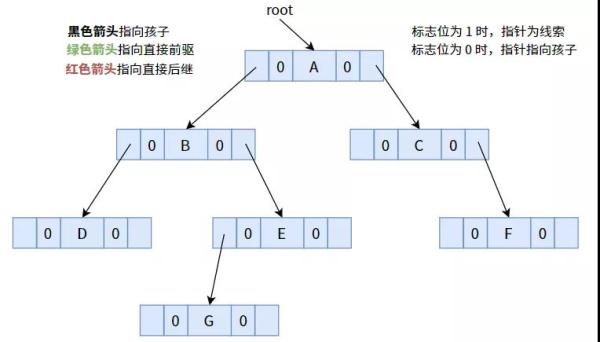
实例
4.1. 中序案件线索化
依照中序遍历顺序案件线索化时,可获得下面的图:
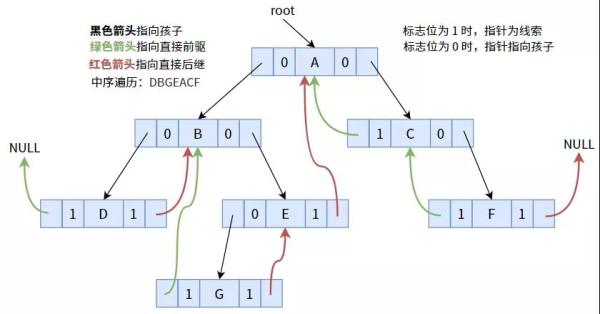
大家先再度确立以下几点:
因此 大家的难题变成了:
表明:我们在解析xml二叉树时,应用到递归算法,因此 在开展案件线索化的情况下,也会应用它。
实际编码以下:
- //全局变量 prev 表针,偏向刚浏览过的节点
- TTreeNode *prev = NULL;
- /**
- * 中序案件线索化
- */
- void inorder_threading(TTreeNode *root)
- {
- if (root == NULL) { //若二叉树为空,看空实际操作
- return;
- }
- inorder_threading(root->left_child);
- if (root->left_child == NULL) {
- root->left_flag = 1;
- root->left_child = prev;
- }
- if (prev != NULL && prev->right_child == NULL) {
- prev->right_flag = 1;
- prev->right_child = root;
- }
- prev = root;
- inorder_threading(root->right_child);
- }
4.2. 先序案件线索化
依照先序次序案件线索化时,可获得下面的图:
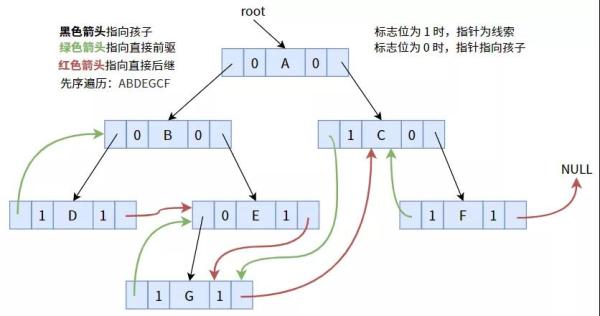
实际编码以下:
- // 全局变量 prev 表针,偏向刚浏览过的节点
- TTreeNode *prev = NULL;
- /**
- * 先序案件线索化
- */
- void preorder_threading(TTreeNode *root)
- {
- if (root == NULL) {
- return;
- }
- if (root->left_child == NULL) {
- root->left_flag = 1;
- root->left_child = prev;
- }
- if (prev != NULL && prev->right_child == NULL) {
- prev->right_flag = 1;
- prev->right_child = root;
- }
- prev = root;
- if (root->left_flag == 0) {
- preorder_threading(root->left_child);
- }
- if (root->right_flag == 0) {
- preorder_threading(root->right_child);
- }
- }
4.3. 之后案件线索化
依照后序遍历顺序案件线索化时,可获得下面的图:
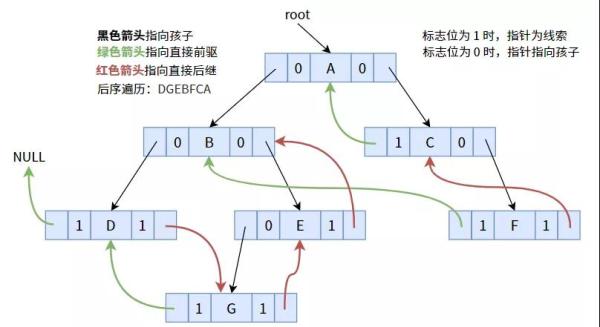
实际编码以下:
- //全局变量 prev 表针,偏向刚浏览过的节点
- TTreeNode *prev = NULL;
- /**
- * 之后案件线索化
- */
- void postorder_threading(TTreeNode *root)
- {
- if (root == NULL) {
- return;
- }
- postorder_threading(root->left_child);
- postorder_threading(root->right_child);
- if (root->left_child == NULL) {
- root->left_flag = 1;
- root->left_child = prev;
- }
- if (prev != NULL && prev->right_child == NULL) {
- prev->right_flag = 1;
- prev->right_child = root;
- }
- prev = root;
- }
线索二叉树灵活运用了二叉树中的空指针域,给与二叉树一个新特点——根据一次解析xml开展案件线索化时,二叉树中就能储存其节点中间的前轮驱动和后续关联。
因此 ,如果我们必须经常解析xml二叉树,搜索某一节点的立即前轮驱动或后续节点,应用线索二叉树是十分适合的。
除此之外,因为编码牵涉到递归算法,第一次触碰很有可能不太好了解,我们可以依靠中断点开展调节,细腻观查案件线索化的全部全过程来协助了解。





