

文中转载微信公众平台「云计算技术与数仓」,创作者西贝莜面村。转截文中请联络云计算技术与数仓微信公众号。
文中会对HBase的基本概念开展分析,根据文中你能掌握到:
温馨提醒:文中內容较长,假如感觉有效,提议个人收藏。此外还记得共享、关注点赞、在看,素质三连哦!
HBase是在GoogleBigTable的基本以上开展开源系统完成的,是一个高靠谱、性能卓越、朝向列、可伸缩式的分布式系统数据库查询,能够用于储存非结构型和半结构型的稀少数据信息。HBase适用集成电路工艺数据储存,能够根据水准拓展的方法解决超出十亿行数据信息和上百万列元素组成的数据分析表。
BigTable是一个分布式系统系统软件,运用Google明确提出的MapReduce分布式系统并行处理实体模型来解决海量信息,应用Google分布式存储GFS做为最底层的数据储存,并选用Chubby出示协作管理与服务,具有普遍的应用性、扩展性、可扩展性及性能卓越性等特性。有关BigTable与HBase的比照,见下表:
| 依靠 | BigTbale | HBase |
|---|---|---|
| 数据储存 | GFS | HDFS |
| 数据处理方法 | MapReduce | Hadoop的MapReduce |
| 协作服务项目 | Chubby | Zookeeper |
2000年,Berkerly高校有一位Eric Brewer专家教授明确提出了一个CAP基础理论,在2002年,麻省理工大学的Seth Gilbert(赛斯·吉尔伯特)和Nancy Lynch(南希·林奇)发布了布鲁尔猜测的证实,证实了CAP基础理论的准确性。说白了CAP基础理论,就是指针对一个分布式计算系统软件而言,不太可能另外达到下列三点:
相当于全部连接点浏览同一份全新的数据信息团本。即一切一个读实际操作一直可以读到以前进行的写实际操作的結果,换句话说,在分布式系统自然环境中,不一样连接点浏览的数据信息是一致的。
每一次要求都能获得到非错的回应——可是不确保获得的数据信息为最新数据。即迅速读取数据,能够在明确的時间内回到实际操作結果。
以预期效果来讲,系统分区等同于对通讯的期限规定。系统软件假如不可以在期限内达到数据信息一致性,就代表着发生了系统分区的状况,务必就当今实际操作在C和A中间作出挑选。即指当发生互联网系统分区时(系统软件中的一部分连接点没法与别的的连接点开展通讯),分离出来的系统软件也可以一切正常运作,即稳定性。

如上图所述所显示:一个分布式系统的系统软件不太可能另外达到一致性、易用性和系统分区容错性,数最多另外达到2个。当解决CAP的难题时,能够有一下好多个挑选:
说白了NoSQL,即Not Only SQL的简称,意思是不只是SQL。上边提及的CAP基础理论恰好是NoSQL的设计原理。那麼,怎么会盛行NoSQL数据库查询呢?由于WEB2.0及其互联网时代的来临,关联型数据库查询愈来愈不可以满足需求。互联网大数据、物联网技术、移动互联和云计算技术的发展趋势,促使非结构型的数据信息占比达到90%之上,关联型数据库查询因为实体模型不灵便及其拓展水准较弱,在应对互联网大数据时,显现出了愈来愈多的缺点。从而NoSQL数据库查询应时而生,能够更好地达到了互联网时代及WEB2.0的要求。
应对WEB2.0及其互联网大数据的挑戰,关联型数据库查询在下列好多个层面主要表现较差:
WEB2.0时代,尤其是移动互联的发展趋势,UGC(客户转化成內容,User Generated Content)及其PGC(群众转化成內容,Public Generated Content)占有了大家的日常。目前,自媒体平台发展趋势蓬勃发展,基本上每一个人都变成內容的创始者,例如博闻、评价、建议、新闻消息、视頻这些,不一而足。由此可见,这种数据信息造成的速率之快,信息量之大。例如新浪微博、微信公众号、又或者是淘宝网,在一分钟内造成的数据信息很有可能便会十分的令人震惊,应对这种上千万、亿级的数据信息纪录,关联型数据库查询的查看高效率显而易见是不可以接纳的。
WEB1.0时代,绝大多数是静态页面(即出示什么就看啥),进而在规模性客户浏览时,能够完成不错的回应工作能力。可是,在WEB2.0时代,注重的是客户的易用性(客户造就內容),全部信息内容都必须客观事实动态性转化成,会导致分布式系统的数据库查询浏览,很有可能每秒钟上万次的读写能力要求,针对许多关联型数据库查询来讲,这表明是承受不住的。
在现如今娱乐至死的时期,热点话题(吸引人目光,达到猎奇心理)会招来一窝蜂的总流量,例如新浪微博曝光某明星出轨,热搜会快速招来大量客户看热闹(别名网络喷子),进而造成很多的互动交流沟通交流(蹭热点),这种都是会导致数据库查询的读写能力负载大幅度提升,进而必须数据库查询可以在短期内内快速提高特性以解决突发性要求(终究宕机遇十分危害户感受)。可是关联型数据库查询一般无法水准拓展,不能够像网页服务器和网站服务器那样简单地根据提升大量的硬件配置和服务项目连接点来拓展特性和负荷工作能力。
综上所述,NoSQL数据库查询应时而生,是IT发展趋势的必定。
特性
HBase 并不是 最后一致性(eventually consistent) 数据储存. 这让它很合适髙速记数汇聚类每日任务
HBase 表根据region遍布在群集中。数据信息提高时,region会全自动切分并再次遍布
HBase 适用该设备外HDFS 做为它的分布式存储
HBase 根据MapReduce适用大高并发解决, HBase 能够另外做源(Source)和汇(Sink)
HBase 适用便于应用的 Java API 开展程序编写浏览
适用Thrift 和 REST 的方法浏览HBase
HBase适用 Block Cache 和 布隆过滤器开展查看提升,提高查看特性
HBase出示内嵌的用以运维管理的网页页面和JMX 指标值
HBase并不宜全部情景
最先,**信息量层面 **。相信有充足多数据信息,如果有上亿或十亿行数据信息,最少单表信息量超出干万,HBase会是一个非常好的挑选。假如仅有过千或几百万行,用传统式的RDBMS可能是更强的挑选。
次之,关联型数据库查询特点层面。相信可以不依靠全部RDBMS的附加特点 (如列基本数据类型、二级数据库索引、事务管理、高級数据库架构等) 。一个创建在RDBMS上运用,并不可以根据简易的更改JDBC驱动器就能转移到HBase,必须一次彻底的再次设计方案。
再度,硬件配置层面。相信您有充足硬件配置。例如因为HDFS 的默认设置团本是3,因此 一般最少五个数据信息连接点才可以充分发挥其特点,此外 也要再加上一个 NameNode连接点。
最终,数据统计分析层面。数据统计分析是HBase的薄弱点,由于针对HBase甚至全部NoSQL生态链而言,大部分全是不兼容表关系的。假如关键要求是数据统计分析,例如做表格,显而易见HBase不是太适合的。
HBase是一个稀少、多维、分布式锁储存的投射表,选用的row key、列族、列限制合乎时间格式开展数据库索引,每一个cell的值全是字节数二维数组byte[]。掌握HBase必须先了解下边的一些定义:
Namespace,即类名,是表的逻辑性排序,类似关联型数据库查询智能管理系统的database。HBase存有2个预订义的独特的类名:hbase和default,在其中hbase归属于系统软件类名,用于储存HBase的內部的表。default归属于默认设置的类名,即假如建表时不特定类名,则默认设置应用default。
由列和行构成,列区划为数个列族
row key是未解释的字节数二维数组,在HBase內部,row key是按字典排序由低到高储存在表格中的。每一个HBase的表由多个行构成,每一个行由行键(row key)标志。能够运用这一特点,将常常一起载入的行储存在一起。
HBase中,列是由列族开展机构的。一个列族全部列组员是拥有同样的作为前缀,例如,列courses:history 和 courses:math全是 列族 courses的组员。灶具(:)是列族的分节符,用于区别前缀和字段名。列族务必在表创建的情况下申明,而列则能够在应用时开展申明。此外,储存在一个列族中的全部数据信息,一般都具备同样的基本数据类型,这能够巨大提升数据信息的压缩系数。在物理学上,一个的列族组员在系统文件上全是储存在一起。
列族里边的数据信息根据列限定符来精准定位。列一般不用在创建表时就要界定,也不用在不一样行中间保持一致。列沒有确立的基本数据类型,一直被视作字节数二维数组byte[]。
表格中,即根据row key、列族、列明确的实际储存的数据信息。表格中中储存的数据信息都没有确立的基本数据类型,总被视作字节数二维数组byte[]。此外,每一个表格中的数据信息是多版本号的,每一个版本号会相匹配一个时间格式。
因为HBase的表数据信息是具备版本号的,这种版本号是根据时间格式开展标志的。每一次对一个表格中开展改动或删掉时,HBase会全自动为其转化成并储存一个时间格式。一个表格中的不一样版本号是依据时间格式降序的次序开展储存的,即优先选择载入全新的数据信息。
有关HBase的数据库系统,详细下面的图:

在HBase数据模型中,一个表能够被看作是一个稀少的、多维的投射关联,如下图所显示:

如以上所显示:
该表包括二行数据信息,各自为com.cnn.www和com.example.www;
三个列族,各自为:contents, anchor 和people。
针对第一行数据信息(相匹配的row key为com.cnn.www),列族anchor包括多列:anchor:cssnsi.com和anchor:my.look.ca;列族contents包括一列:contents:html;
针对第一行数据信息(相匹配的row key为com.cnn.www),包括五个版本号的数据信息
针对第二行数据信息(相匹配的row key为com.example.www),包括一个版本号的数据信息
以上中能够根据一个四维平面坐标一个表格中数据信息:[row key,列族,列,时间格式],例如[com.cnn.www,contents,contents:html,t6]
从数据模型上看,HBase的表是稀少的。在物理学储存的情况下,是依照列族开展储存的。一个列限定符(column_family:column_qualifier)能够被随时随地加上到早已存有的列族上。
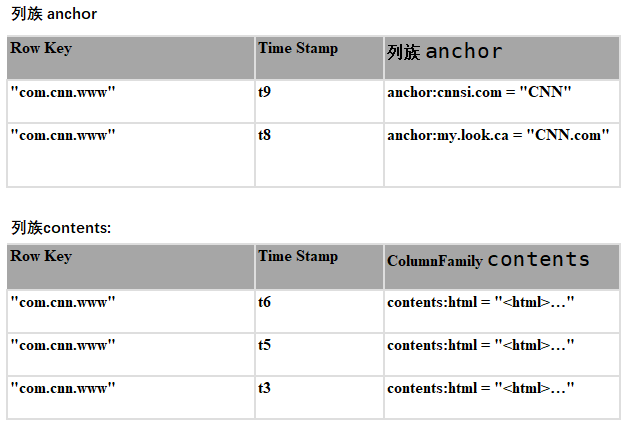
从概念模型上看,数据模型中存有的空表格中是不容易被储存的。例如要浏览contents:html,时间格式为t8,则不容易传参。特别注意的是,假如浏览数据信息时沒有特定时间格式,则默认设置浏览最新版的数据信息,由于数据信息是依照版本号时间格式降序排序的。
如以上:假如浏览行com.cnn.www,列contents:html,在沒有特定时间格式的状况下,则回到t6相匹配的数据信息;同样假如浏览anchor:cnnsi.com,则回到t9相匹配的数据信息。
根据上边的叙述,应当对HBase拥有一定的掌握。如今我们在看来一下HBase的宏观经济构架,如下图:
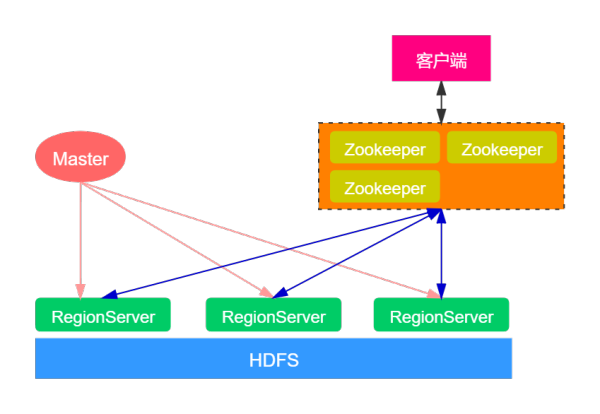
大家先从宏观经济的角度观察一下HBase的总体构架。从HBase的布署构架上而言,HBase有二种网络服务器:Master网络服务器和RegionServer网络服务器。一般一个HBase群集有一个Master网络服务器和好多个RegionServer网络服务器。
Master网络服务器承担维护保养表结构信息内容,具体的数据信息都储存在RegionServer网络服务器上。在HBase的群集中,手机客户端读取数据由手机客户端传送数据RegionServer的,因此 你能发觉Master挂了以后你仍然能够查看数据信息,可是不可以建立新的表了。
大家都了解,在Hadoop选用的是master-slave构架,即namenode连接点为主导连接点,datanode连接点为从连接点。namenode连接点针对hadoop群集来讲尤为重要,假如namenode连接点挂掉,那麼全部群集也就偏瘫了。
可是,在HBase群集中,Master服务项目的功效并沒有那麼的关键。尽管是Master连接点,实际上并并不是一个leader的人物角色。Master服务项目更好像一个‘杂活’的,类似一个輔助者的人物角色。由于在我们联接HBase群集时,手机客户端会立即从Zookeeper中获得RegionServer的详细地址,随后从RegionServer中获得要想的数据信息,不用历经Master连接点。此外,在我们向HBase表格中插进数据信息、删掉数据信息等实际操作时,也全是立即跟RegionServer互动的,不用Master服务项目参加。
那麼,Master服务项目有什么作用呢?Master只承担各种各样相互配合,例如建表、删表、挪动Region、合拼等实际操作。这种实际操作有一个关联性的难题:便是必须跨RegionServer。因此 ,HBase就将这种工作中分派给了Master服务项目。这类构造的益处是大幅度降低了群集对Master的依靠。而Master连接点一般只有一个到2个,一旦服务器宕机,假如群集对Master的依存度非常大,那麼便会造成服务器宕机难题。在HBase中即便Master服务器宕机了,群集仍然能够一切正常地运作,仍然能够储存和删掉数据信息。
RegionServer便是储放Region的器皿,形象化上说便是网络服务器上的一个服务项目。RegionServer是真真正正储存数据信息的连接点,最后储存在分布式存储HDFS。当手机客户端从ZooKeeper获得RegionServer的详细地址后,它会立即从RegionServer读取数据。针对HBase群集来讲,其必要性要比Master服务项目大。
RegionServer十分依靠ZooKeeper服务项目,ZooKeeper在HBase中饰演的人物角色相近一个大管家。ZooKeeper管理方法了HBase全部RegionServer的信息内容,包含实际的数据信息段储放在哪个RegionServer上。手机客户端每一次与HBase联接,实际上全是先与ZooKeeper通讯,查看出哪一个RegionServer必须联接,随后再联接RegionServer。
我们可以根据zkCli浏览hbase连接点的数据信息,根据下边取名能够获得hbase:meta表的信息内容:
[zk: localhost:2181(CONNECTED) 17] get /hbase/meta-region-server
简易小结Zookeeper在HBase群集中的功效以下:针对服务器端,是完成群集融洽与操纵的关键依靠。针对手机客户端,是查看与实际操作数据信息不可或缺的一部分。
必须留意的是:当Master服务项目挂了时,仍然能够开展能读能写实际操作;可是把ZooKeeper一旦挂了,就不可以获取数据了,由于获取数据所必须的元数据分析表hbase:meata的部位储存在ZooKeeper上。由此可见zookeeper针对HBase来讲是尤为重要的。
Region
Region便是一段数据信息的结合。HBase中的表一般有着一个到好几个Region。Region不可以跨网络服务器,一个RegionServer上有一个或是好几个Region。当逐渐创建表时,信息量小的时候,一个Region足够储存全部数据信息,直到信息量慢慢提升,会拆分成好几个region;当HBase在开展web服务的情况下,也是有很有可能会从一台RegionServer上把Region挪动到另一台RegionServer上。Region是储存在HDFS的,它的全部数据信息存储实际操作全是启用了HDFS的手机客户端插口来完成的。一个Region就等同于关联型数据库查询中分区表的一个系统分区。
上一小标题对HBase的总体构架开展了表明,下面再看一下內部关键点,如下图所显示:展现了一台RegionServer的內部构架。
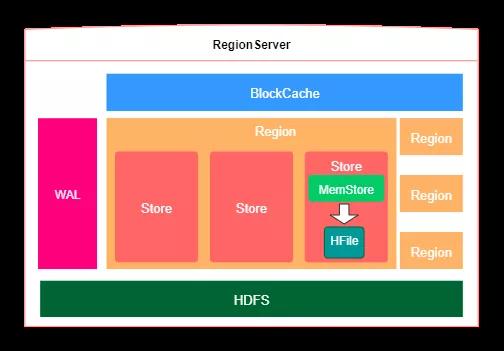
如上图所述所显示:一个RegionServer能够储存好几个region,Region等同于一个数据信息分块。每一个Region都是有起 始rowkey和完毕rowkey,意味着了它所储存的row范畴。在一个region內部,包含好几个store,在其中一个store相匹配一个列族,每一个store的內部又包括一个MemStore,关键承担数据信息排列,等超出一定阀值以后将MemStore的数据信息刷出HFile文档,HFile文档时最后储存数据信息的地区。
特别注意的是:一台RegionServer同用一个WAL(Write-Ahead Log)预写日志,假如打开了WAL,那麼当写数据信息的时候会先写进WAL,能够具有容错机制功效。WAL是一个商业保险体制,数据信息在提到Memstore以前,先被提到WAL了。那样当常见故障修复的情况下能够从WAL中恢复数据库。此外,每一个Store都是有一个MemStore,用以数据信息排列。一台RegionServer也只有一个BlockCache,用以读取数据是开展缓存文件。
**Write Ahead Log (WAL)**会纪录HBase中的全部数据信息,WAL具有容错机制修复的功效,并并不是务必的选择项。在HDFS上,WAL的默认设置途径是/hbase/WALs/,客户能够根据hbase.wal.dir开展配备。
WAL默认设置是打开的,假如关掉,能够应用下边的指令Mutation.setDurability(Durability.SKIP_WAL)。WAL适用多线程和同歩的载入方法,多线程方法根据启用下边的方式Mutation.setDurability(Durability.ASYNC_WAL)。同歩方法根据启用下边的方式:Mutation.setDurability(Durability.SYNC_WAL),在其中同歩方法是默认设置的方法。
有关多线程WAL,当有Put、Delete、Append实际操作时,并不会马上开启同歩数据信息。只是要直到一定的间隔时间,该间隔时间能够根据主要参数hbase.regionserver.optionallogflushinterval开展设置,默认设置是100ms。
每一个Store中有一个MemStore案例。数据信息载入WAL以后便会被放进MemStore。MemStore是运行内存的储存目标,仅有当MemStore满了的情况下才会将数据信息刷写(flush)到HFile中。
为了更好地让数据信息顺序存储进而提升载入高效率,HBase应用了LSM树形结构来储存数据信息。数据信息会先在Memstore中 梳理成LSM树,最终再刷写到HFile上。
有关MemStore,非常容易令人搞混。数据信息在被刷出HFile以前,早已被储存到HDFS的WAL到了,那麼为何也要在放进MemStore呢?其实不是很难,大家都了解HDFS是不可以改动的,而HBase的数据信息也是依照Row Key开展排列的,实际上这一排列的全过程便是在MemStore中开展的。特别注意的是:MemStore的功效并不是为了更好地加速写速率,只是为了更好地对Row Key开展排列。
HFile是数据储存的具体媒介,大家建立的全部表、列等数据信息都储存在HFile里边。当Memstore做到一定阈值,或是做到了刷写间隔时间阈值的情况下,HBaes会被这一Memstore的內容刷写到HDFS系统软件上,称之为一个储存在电脑硬盘上的HFile文档。到此,大家数据信息真真正正的被分布式锁到电脑硬盘上。
在逐渐解读HBase的数据信息读写能力步骤以前,先看来一下Region是如何定位的。我们知道Region是HBase十分关键的一个定义,Region储存在RegionServer中,那麼手机客户端在存取数据时是怎样定位到所必须的region呢?有关这个问题,老版本的HBase与最新版本的HBase各有不同。
老版本的HBase选用的是为三层查看构架,如下图所显示:
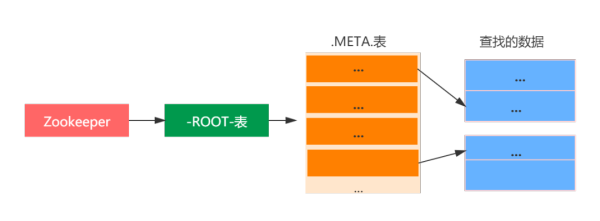
如上图所述:第一层精准定位是Zookeeper中的连接点数据信息,纪录了-ROOT-表的位置信息;
第二层-ROOT-表纪录了.META.region位置信息,-ROOT-表只有一个region,根据-ROOT-表能够浏览.META.表格中的数据信息
第三层.META.表,纪录了客户数据分析表的region位置信息,.META.表能够有好几个region。
全部查看流程以下:
第一步:客户根据搜索zk(ZooKeeper)的/hbase/root-regionserver连接点来了解-ROOT-表的RegionServer部位。
第二步:浏览-ROOT-表,搜索所必须的数据分析表的元数据信息存有哪一个.META.表里,这一.META.表在哪个RegionServer上。
第四步:浏览.META.表看来你需要查看的行键在什么Region范畴里边。
第五步:联接实际的数据信息所属的RegionServer,这一一步才逐渐在很正的查看数据信息。
老版本的HBase寻址方式存有许多缺点,在最新版本中开展了改善。选用的是二级寻址方式的方法,只是应用 hbase:meta表来精准定位region,那麼 从哪里获得hbase:meta的信息内容呢,回答是zookeeper。在zookeeper中存有一个/hbase/meta-region-server连接点,能够获得hbase:meta表的位置信息,随后根据hbase:meta表查看所必须数据信息所属的region位置信息。
全部查看流程以下:
第一步:手机客户端先根据ZooKeeper的/hbase/meta-region-server连接点查看hbase:meta表的部位。
第二步:手机客户端联接hbase:meta表所属的RegionServer。hbase:meta表储存了全部Region的行键范畴信息内容,根据这一表就可以查看出你需要存储的rowkey归属于哪一个Region的范畴里边,及其这一Region归属于哪一个 RegionServer。
第三步:获得这种信息内容后,手机客户端就可以传送数据有着你需要存储的rowkey的RegionServer,并立即对其实际操作。
第四步:手机客户端会把meta信息内容缓存文件起來,下一次实际操作就不用开展之上载入hbase:meta的流程了。
- public class Example {
- private static final String TABLE_NAME = "MY_TABLE_NAME_TOO";
- private static final String CF_DEFAULT = "DEFAULT_COLUMN_FAMILY";
- public static void createOrOverwrite(Admin admin, HTableDescriptor table) throws IOException {
- if (admin.tableExists(table.getTableName())) {
- admin.disableTable(table.getTableName());
- admin.deleteTable(table.getTableName());
- }
- admin.createTable(table);
- }
- public static void createSchemaTables(Configuration config) throws IOException {
- try (Connection connection = ConnectionFactory.createConnection(config);
- Admin admin = connection.getAdmin()) {
- HTableDescriptor table = new HTableDescriptor(TableName.valueOf(TABLE_NAME));
- table.addFamily(new HColumnDescriptor(CF_DEFAULT).setCompressionType(Algorithm.NONE));
- System.out.print("Creating table. ");
- createOrOverwrite(admin, table);
- System.out.println(" Done.");
- }
- }
- public static void modifySchema (Configuration config) throws IOException {
- try (Connection connection = ConnectionFactory.createConnection(config);
- Admin admin = connection.getAdmin()) {
- TableName tableName = TableName.valueOf(TABLE_NAME);
- if (!admin.tableExists(tableName)) {
- System.out.println("Table does not exist.");
- System.exit(-1);
- }
- HTableDescriptor table = admin.getTableDescriptor(tableName);
- // 升级table
- HColumnDescriptor newColumn = new HColumnDescriptor("NEWCF");
- newColumn.setCompactionCompressionType(Algorithm.GZ);
- newColumn.setMaxVersions(HConstants.ALL_VERSIONS);
- admin.addColumn(tableName, newColumn);
- // 升级column family
- HColumnDescriptor existingColumn = new HColumnDescriptor(CF_DEFAULT);
- existingColumn.setCompactionCompressionType(Algorithm.GZ);
- existingColumn.setMaxVersions(HConstants.ALL_VERSIONS);
- table.modifyFamily(existingColumn);
- admin.modifyTable(tableName, table);
- // 禁止使用table
- admin.disableTable(tableName);
- // 删掉column family
- admin.deleteColumn(tableName, CF_DEFAULT.getBytes("UTF-8"));
- // 删除表,最先要禁止使用表
- admin.deleteTable(tableName);
- }
- }
- public static void main(String... args) throws IOException {
- Configuration config = HBaseConfiguration.create();
- config.addResource(new Path(System.getenv("HBASE_CONF_DIR"), "hbase-site.xml"));
- config.addResource(new Path(System.getenv("HADOOP_CONF_DIR"), "core-site.xml"));
- createSchemaTables(config);
- modifySchema(config);
- }
- }
Q1:MemStore的功效是啥?
在HBase中,一个表能够有好几个列族,一个列族在物理学上是储存在一起的,一个列族会相匹配一个store,在store的內部会存有一个MemStore,其功效并并不是为了更好地提高读写能力速率,只是为了更好地对RowKey开展排列。我们知道,HBase的数据信息是储存在HDFS上的,而HDFS是不兼容改动的,HBase为了更好地按RowKey开展排列,最先会将数据信息载入MemStore,数据信息会先在Memstore中梳理成LSM树,最终再刷写到HFile上。
总而言之一句话:Memstore的完成目地并不是加快数据信息载入或载入,只是保持算法设计。
Q2:获取数据的时候会先从MemStore载入吗?
MemStore的功效是为了更好地按RowKey开展排列,其功效并不是为了更好地提高载入速率的。获取数据的情况下是有专业的缓存文件叫BlockCache,假如打开了BlockCache,便是读熟BlockCache,随后才算是读HFile Memstore的数据信息。
Q3:BlockCache有什么作用?
块缓存文件(BlockCache)应用运行内存来纪录数据信息,适用提高载入特性。当打开了块缓存文件后,HBase会优先选择从块缓存文件中查看是不是有纪录,要是没有才去查找储存在电脑硬盘上的HFile。
特别注意的是,一个RegionServer只有一个BlockCache。BlockCache并不是数据储存的务必构成部分,仅仅用于提升载入特性的。
BlockCache的基本概念是:在学要求到HBase以后,会先试着查看BlockCache,假如获得不上需要的数据信息,就要HFile和Memstore中去获得。假如获得到,则在回到数据信息的另外把Block块缓存文件到BlockCache中。
Q4:HBase是如何删除数据信息的?
HBase删除历史记录并并不是确实删除了数据信息,只是标志了一个墓牌标识(tombstone marker),把这个版本号连着以前的版本号都标识为不由此可见了。它是为了更好地特性考虑,那样HBase就可以按时去清除这种早已被删掉的纪录,而无需每一次都开展删掉实际操作。说白了按时清除,便是依照一定时间周期在HBase做全自动合拼(compaction,HBase梳理储存文档时的一个实际操作,会把好几个文档块合拼成一个文档)。那样删掉实际操作针对HBase的特性危害被降至了最少,就算是在很高的高并发负荷下很多删除历史记录也是OK的。
合拼实际操作分成二种:Minor Compaction和Major Compaction。
在其中Minor Compaction是将Store中好几个HFile合拼为一个HFile。在这个全过程中做到TTL的数据信息会被清除,可是被手动式删掉的数据信息不容易被清除。这类合拼开启頻率较高。
而Major Compaction合拼Store中的全部HFile为一个HFile。在这个全过程中被手动式删掉的数据信息会被真真正正地清除。另外被删掉的也有表格中内超出MaxVersions的版本号数据信息。这类合拼开启頻率较低,默认设置为7天一次。但是因为Major Compaction耗费的特性很大,一般提议手动式操纵MajorCompaction的机会。
必须留意的是:Major Compaction删掉的是这些带墓牌标识的数据信息,而Minor Compaction合拼的情况下立即会忽视过期数据文档,因此 到期的这种文档会在Minor Compaction的情况下就被删掉。
Q5:为何HBase具备性能卓越的阅读能力?
由于HBase应用了一种LSM的存储结构,在LSM树的完成方法中,会在数据储存以前先向数据信息开展排列。LSM树是Google BigTable和HBase的基本上储存优化算法,它是传统式关联型数据库查询的B 树的改善。优化算法的关键取决于尽可能确保数据是顺序存储到硬盘上的,而且会出现頻率地对数据信息开展梳理,保证 其次序性。
LSM树便是一堆小树苗,在运行内存中的小树苗即memstore,每一次flush,运行内存中的memstore变为硬盘上一个新的storefile。这类大批量的存取数据促使HBase的特性较高。
Q6:Store与列簇是啥关联?
Region是HBase的关键控制模块,而Store则是Region的关键控制模块。每一个Store相匹配了表中的一个列族储存。每一个Store包括一个MemStore和数个HFile。
Q7:WAL是RegionServer共享资源的,或是Region等级共享资源的?
在HBase中,每一个RegionServer只必须维护保养一个WAL,全部Region目标同用一个WAL,而不是每一个Region都维护保养一个WAL。这类方法针对好几个Region的升级实际操作所产生的的日志改动,只必须不断增加到单独日志文档中,不用另外开启并载入好几个日志文档,那样能够降低硬盘寻址方式频次,提升写特性。
可是这类方法也存有一个缺陷,假如RegionServer产生常见故障,为了更好地修复其上的Region目标,必须将RegionServer上的WAL依照其隶属的Region目标开展分拆,随后派发到别的RegionServer上实行修复实际操作。
Q8:Master挂了以后,还能查看数据信息吗?
能够的。Master服务项目关键承担表和Region的管理方面。关键功效有:
手机客户端浏览HBase时,不用Master的参加,只必须联接zookeeper获得hbase:meta详细地址,随后传送数据RegionServer开展数据信息存取数据,Master只是维护保养表和Region的元数据信息,负荷不大。可是Master连接点也不可以长期的服务器宕机。
文中最先从Google的BigTable谈起,随后详细介绍了CAP有关基础理论,并剖析了NoSQL发生的缘故。然后对HBase的数据库系统开展了分析,随后详细说明了HBase的基本原理和管理机制。最终得出了手机客户端API的基本上应用,并对普遍的、易搞混的知识要点开展了表述。





