

各位好!,我是武哥。它是《吃透 MQ 系列》的第二弹,有一些珊珊来迟,后台管理被很多阅读者催更了,实在是很抱歉!
本文拖更了好几个星期,最初的念头是:紧紧围绕每一个实际的消息中间件,不但要写透,并且要操纵好篇数,写下来发觉确实真的很难,二者难以兼顾。
最终决策或是分为数篇写吧。一方面,能加速下輸出頻率;另一方面,大伙儿也更非常容易消化吸收。
废话不多说了,第二弹逐渐发班。
《吃透 MQ 》的开场 紧紧围绕 MQ 「一发一存一消費」的实质进行,解读了 MQ 的通用性专业知识,另外系统化地回应了:怎样下手设计方案一个 MQ?
从本文逐渐,我能解读实际的消息中间件,往往挑选从 Kafka 逐渐,有 3 点考虑到:
第一,RocketMQ 和 Kafka 是现阶段最受欢迎的二种消息中间件,互联网公司运用更为普遍,将做为本系列产品的关键。
第二,从 MQ 的发展史看来,Kafka 在于 RocketMQ 问世,而且阿里巴巴精英团队在完成 RocketMQ 时,充足参考了 Kafka 的设计方案观念。把握了 Kafka 的结构设计,后边再去了解 RocketMQ 会非常容易许多。

第三,Kafka 实际上是一个轻量的 MQ,它具有 MQ 最基本的工作能力,可是在延迟时间序列、再试体制等高級特点上仍未做适用,因而减少了完成复杂性。从 Kafka 下手,有益于大伙儿迅速把握 MQ 最关键的物品。
交待完情况,下边请大伙儿跟着的构思,一起循序渐进地剖析下 Kafka。
在详细分析一门技术性以前,不建议上去就要掌握构架及其关键技术,只是先搞清楚它是啥?它是为了更好地处理什么问题而造成的?
把握这种情况专业知识后,有益于大家了解它身后的设计方案考虑到及其设计方案观念。
在写本文时,我查看了许多材料,有关 Kafka 的界定可以说五花八门,不细心反复推敲非常容易一脸懵逼,我认为必须带大伙儿捋一捋。
大家先看一下 Kafka 官方网站为自己下的界定:
翻译中文便是:Apache Kafka 是一个开源系统的分布式系统流解决服务平台。
Kafka 并不是一个信息系统软件吗?为何被称作分布式系统的流解决服务平台呢?这二者是一回事儿吗?
一定有阅读者会出现那样的疑惑,要表述这个问题,必须先从 Kafka 的问世情况谈起。
Kafka 最初实际上是 Linkedin 內部卵化的新项目,在设计方案之初是被作为「数据信息管路」,用以解决下列二种情景:
能够见到这二种数据信息都归属于日志范围,特性是:数据信息即时生产制造,并且信息量非常大。
Linkedin 最开始也试着试过 ActiveMQ 来处理传输数据难题,可是特性没法符合要求,随后才决策自研 Kafka。
因此从一开始,Kafka 便是为即时日志流为之的。了解了这一情况,就不难理解 Kafka 与流数据的关联了,及其 Kafka 为啥互联网大数据行业有这般普遍的运用?也是由于它最开始便是为处理互联网大数据的管路难题而问世的。
然后再表述下:为何 Kafka 被官方网界定成流解决服务平台呢?它不就出示了一个数据通道工作能力吗,如何还和服务平台扯上关联了?
这是由于 Kafka 从 0.8 版本号逐渐,就早已在出示一些和数据处理方法相关的部件了,例如:
由此可见 Kafka 的欲望不仅是一个信息系统软件,它早已在往「即时流解决服务平台」方位发展趋势了。
此刻,再回家看 Kafka 的官方网站详细介绍提及的 3 种工作能力,也不难理解了:
那样,kafka 的发展趋势历史时间和界定基本上缕清了。自然,这一系列产品只是关心 Kafka 的前二种工作能力,由于这二种工作能力都和 MQ 强有关。
了解了 Kafka 的精准定位及其它的问世情况,然后大家剖析下 Kafka 的设计方案观念。
上一篇文章中我提及过:要弄懂一个MQ,提议从「信息实体模型」这类最关键的基础理论方面下手,而不是一上去就要看技术架构,更不必直接进入关键技术。
说白了信息实体模型,能够了解成一种逻辑结构,它是技术架构直往上的一层抽象性,通常暗含了最关键的设计方案观念。
下边大家试着剖析下 Kafka 的信息实体模型,看一下它到底是怎样演变来的?
最先,为了更好地将一份信息数据信息分发送给好几个顾客,而且每一个顾客都能接到全量的信息,很当然的想起了广播节目。

随后难题发生了:来一条信息,就广播节目给全部顾客,但并不是每一个顾客都要想所有的信息,例如顾客 A 只要想信息1、2、3,顾客 B 只要想信息4、5、6,此刻应该怎么办呢?
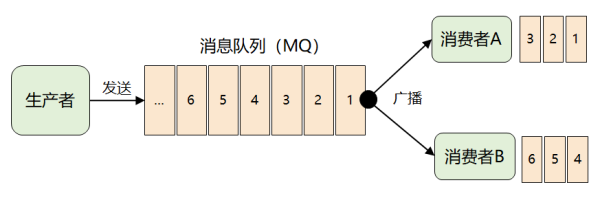
这个问题的关键环节取决于:MQ 不理解信息的词义,它没办法保证对信息开展归类递送。
这时,MQ 想起了一个很聪慧的方法:它将难点立即抛给了经营者,规定经营者在推送信息时,对信息开展逻辑性上的归类,因而就演变出了大家熟识的 Topic 及其公布-定阅实体模型。
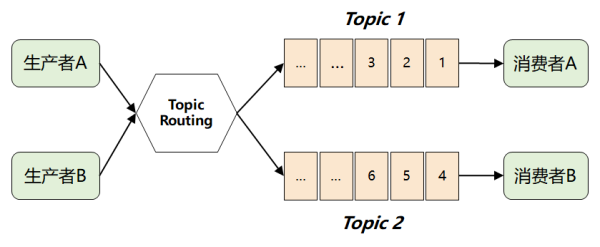
那样,顾客只必须定阅自身很感兴趣的 Topic,随后从 Topic 中获得信息就可以。
可是那样干了以后,依然存有一个难题:倘若好几个顾客都对同一个 Topic 很感兴趣(如下图中的顾客 C),那又该如何解决呢?

假如选用传统式的序列方式(单播),那当一个顾客从序列中拿走信息后,这条信息便会被删掉,此外一个顾客就拿不到了。
这个时候,很当然又想起下边的解决方法:
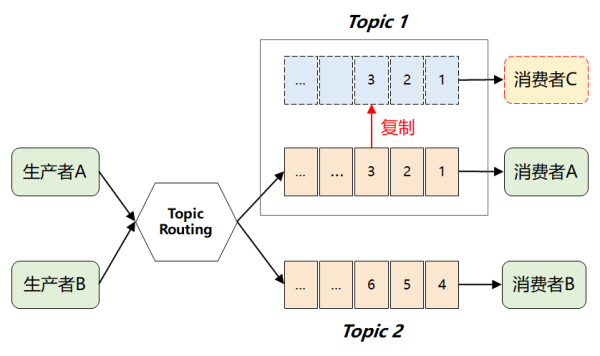
也就是:当 Topic 每提升一个新的顾客,就「拷贝」一个彻底一样的数据信息序列。
那样难题是解决了,可是伴随着中下游顾客总数变多,将引起 MQ 特性的迅速衰退。特别是在针对 Kafka 而言,它在问世之初便是解决互联网大数据情景的,这类拷贝实际操作显而易见成本费太高了。
此刻,就拥有 Kafka 最画龙点晴的一个打法:它将全部信息开展了分布式锁储存,由顾客自身你情我愿,想取哪一个信息,想何时取都可以,只必须传送一个信息的 offset 就可以。
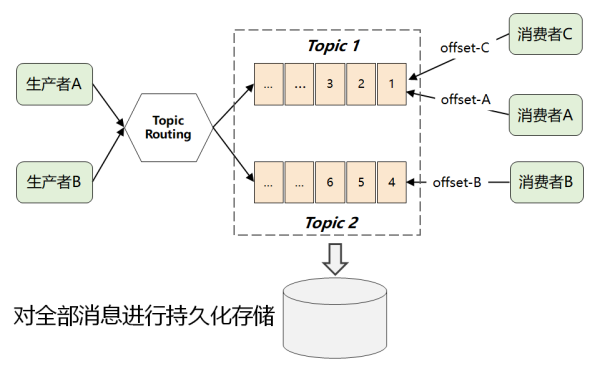
那样一个全局性更改,完全将繁杂的消費难题又返给顾客了,那样促使 Kafka 自身的复杂性大幅度降低,进而为它的性能卓越和高拓展奠定了优良的基本。(它是 Kafka 有别于 ActiveMQ 和 RabbitMQ 最关键的地区)
最终,简单化一下,便是下边这幅图:
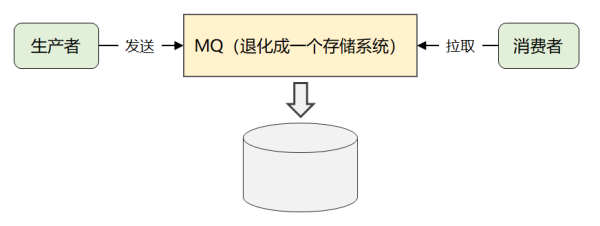
这就是 Kafka 最初的信息实体模型。
这也间接性表述了第二章节目录中:为何官方网会将 Kakfa 另外界定成分布式存储的缘故。
自然 Kafka 的精妙设计方案不是这种,因为篇数缘故,后边的文章内容再然后剖析。
本文从 Kafka 的问世情况讲起,带大伙儿捋清了 Kafka 的界定和它要处理的难题。
此外,一步步剖析了 Kafka 的信息实体模型和设计方案观念,它是 Kafka 最高层的抽象性。
文中转载微信公众平台「武哥漫谈IT」,能够根据下列二维码关心。转截文中请联络武哥漫谈IT微信公众号。






